Setting up for DGE analysis
Ha Tran
06-01-2024
Last updated: 2024-08-02
Checks: 7 0
Knit directory: 5_Treg_uNK/1_analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(12345) was run prior to running the
code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 73ae14f. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Untracked files:
Untracked: .DS_Store
Untracked: .gitignore
Untracked: cellChat.Rmd
Unstaged changes:
Modified: 0_data/rds_plots/deHmap_plots.rds
Modified: 0_data/rds_plots/go_combined_parTerm_dotPlot.rds
Modified: 0_data/rds_plots/go_parTerm_dotPlot.rds
Modified: 0_data/rds_plots/kegg_path_Hmap.rds
Deleted: 1_analysis/cellChat.Rmd
Modified: 3_output/GO_sig.xlsx
Modified: 3_output/KEGG_all.xlsx
Modified: 3_output/KEGG_sig.xlsx
Modified: 3_output/de_genes_all.xlsx
Modified: 3_output/de_genes_sig.xlsx
Modified: 3_output/reactome_all.xlsx
Modified: 3_output/reactome_sig.xlsx
Modified: sampleHeatmap.rds
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (1_analysis/setUp.Rmd) and HTML
(docs/setUp.html) files. If you’ve configured a remote Git
repository (see ?wflow_git_remote), click on the hyperlinks
in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 73ae14f | Ha Tran | 2024-08-02 | Large update with final visualisations |
| html | 73ae14f | Ha Tran | 2024-08-02 | Large update with final visualisations |
| html | e9e7671 | tranmanhha135 | 2024-02-08 | Build site. |
| Rmd | 8da2e31 | tranmanhha135 | 2024-02-08 | workflowr::wflow_publish(here::here("1_analysis/*.Rmd")) |
| html | d8d23ee | tranmanhha135 | 2024-01-13 | im on holiday |
| html | 36aeb85 | Ha Manh Tran | 2024-01-13 | Build site. |
| Rmd | a957cff | Ha Manh Tran | 2024-01-13 | workflowr::wflow_publish(here::here("1_analysis/*Rmd")) |
| Rmd | c78dfac | tranmanhha135 | 2024-01-12 | remote from ipad |
| Rmd | 221e2fa | tranmanhha135 | 2024-01-10 | fixed error |
| html | 221e2fa | tranmanhha135 | 2024-01-10 | fixed error |
| html | 762020e | tranmanhha135 | 2024-01-09 | Build site. |
| Rmd | f2e3750 | tranmanhha135 | 2024-01-08 | completed DE |
| Rmd | 05fa0b3 | tranmanhha135 | 2024-01-06 | added description |
Data Setup
Prior to this analysis, Daniel Thompson (SAGC) performed:
Trimmed using
cutAdaptAligned to GRCm38/mm10 using
STARReads quantification performed with
STAR
# working with data
library(dplyr)
library(magrittr)
library(readr)
library(tibble)
library(reshape2)
library(tidyverse)
library(bookdown)
library(here)
library(scales)
# Visualisation:
library(ggbiplot)
library(ggrepel)
library(grid)
library(cowplot)
library(corrplot)
library(DT)
library(plotly)
library(patchwork)
# Bioconductor packages:
library(AnnotationHub)
library(edgeR)
library(limma)
library(Glimma)
# Fontlib
library(extrafont)rawCount <- readRDS(here::here("0_data/rds_objects/rawCount.rds"))
DT <- readRDS(here::here("0_data/functions/DT.rds"))
# to increase the knitting speed. change to T to save all plots
savePlots <- T
# Theme
bossTheme <- readRDS(here::here("0_data/functions/bossTheme.rds"))
bossTheme_bar <- readRDS(here::here("0_data/functions/bossTheme_bar.rds"))
groupColour <- readRDS(here::here("0_data/functions/groupColour.rds"))
groupColour_dark <- readRDS(here::here("0_data/functions/groupColour_dark.rds"))
# Plotting
convert_to_superscript <- readRDS(here::here("0_data/functions/convert_to_superscript.rds"))
exponent <- readRDS(here::here("0_data/functions/exponent.rds"))
format_y_axis <- readRDS(here::here("0_data/functions/format_y_axis.rds"))Import raw count data
To save time, this will only be performed once at the begining of the analysis. For subsequent analysis, the file will just be loaded.
rawCount <- read_csv(here::here("0_data/rawData/all.counts.genes.csv")) %>% setNames(c("GeneID", "DT1", "DT2", "DT3", "DT4", "DT6", "veh1", "veh2", "veh3", "veh4", "veh5", "veh6", "DT+Treg1", "DT+Treg2", "DT+Treg3", "DT+Treg4", "DT+Treg5")) %>% column_to_rownames("GeneID")
rawCount <- rawCount[!rownames(rawCount) %in% c("ambiguous", "no_feature"),]
saveRDS(rawCount, here::here("0_data/rds_objects/rawCount.rds"))Importing Metadata
There are generally two metadata required for DGE analysis.
metadata about each sample
metadata about each gene
Sample Metadata
The sample metadata can be extracted from the rawCount
column names. These data include sample_id,
sample_group, sample_type.
sampleMeta <- data.frame("sample" = colnames(rawCount),
`group` = c(rep("DT",5),rep("veh",6),rep("DT+Treg",5)),
`rep` = c(1,2,3,4,6,1,2,3,4,5,6,1,2,3,4,5))Gene Metadata
Gene annotation is useful for the DGE analysis as it will provide useful information about the genes. The annotated genes of Mus musculus can be pulled down by using Annotation Hub.
Annotation Hub also has a web service that can be assessed through
the display function. Pulling down the gene annotation can take a long
time, so after the initial run, the annotated genes is saved to a
genes.rds file. To save time, if genes.rds is
already present, don’t run the code chunk.
ah <- AnnotationHub()
ah %>%
subset(grepl("musculus", species)) %>%
subset(rdataclass == "EnsDb")
#viewing web service for annotation hub
BiocHubsShiny::BiocHubsShiny()
# Annotation hub html site was used to identify ID for the latest mouse genome from Ensembl:
# Ensembl 110 EnsDb for Mus musculus (GRCm39/mm39)
ensDb <- ah[["AH113713"]]
genes <- genes(ensDb) %>%
as.data.frame()
#the annotated genes are saved into a RDS object to save computational time in subsequent run of the setUp.Rmd
saveRDS(object = genes,file = here::here("0_data/rds_objects/gene_metadata.rds"))Using the annotated gene list through AnnotationHub(), load into
object called geneMetadata. Filter out all genes that are
present in the rawCount and display the number of unique gene_biotypes
present in the rawCount and geneMetadata
geneMeta <- read_rds(here::here("0_data/rds_objects/gene_metadata.rds"))
#prepare the gene data frame to contain the genes listed in the rownames of 'rawCount' data
geneMeta <- data.frame(gene = rownames(rawCount)) %>%
left_join(geneMeta %>% as.data.frame,
by = c("gene"="gene_name")) %>%
dplyr::distinct(gene, .keep_all=TRUE)
rownames(geneMeta) <- geneMeta$gene
#Using the table function, the details of the genes present in the rawCount data can be summaried.
genes <- geneMeta$gene_biotype %>% table %>% as.data.frame()
colnames(genes) <- c("Gene Biotype", "Frequency")
genes$`Gene Biotype` <- as.character(genes$`Gene Biotype`)
genes$`Gene Biotype`[grep("_", genes$`Gene Biotype`)] <- str_to_sentence(str_replace_all(genes$`Gene Biotype`[grep("_", genes$`Gene Biotype`)], "_", " "))Interactive pie chart
pie <- plot_ly(genes, labels = ~`Gene Biotype`, values = ~`Frequency`, type = 'pie',
textposition = 'inside',
textinfo = 'label+percent',
# insidetextfont = list(color = '#FFFFFF'),
hoverinfo = 'text',
text = ~paste(`Frequency`, ' genes'),
marker = list(colors = colors,line = list(color = '#FFFFFF', width = 1)),
#The 'pull' attribute can also be used to create space between the sectors
showlegend = T)
pie <- pie %>% layout(title = 'Frequency of gene biotype',
xaxis = list(showgrid = FALSE, zeroline = FALSE, showticklabels = FALSE),
yaxis = list(showgrid = FALSE, zeroline = FALSE, showticklabels = FALSE))
pieTable
genes %>% DT(.,caption = "Table 1: Gene biotype")Create DGEList object
Digital Gene Expression List (DGElist) is a R object class often used for differential gene expression analysis as it simplifies plotting, and interaction with data and metadata.
The DGEList object holds the three dataset that have
imported/created, including rawCount data and
sampleMeta and geneMeta metadata.
To further save time and memory, genes that were not expressed across
all samples (i.e., 0 count across all columns) are all
removed
#Create DGElist with rawCOunt and gene data. Remove all genes with 0 expression in all treatment groups
dge <- DGEList(counts = rawCount,
samples = sampleMeta,
genes = geneMeta,
remove.zeros = TRUE
)
dge$samples$group <- factor(dge$samples$group, levels = c("veh", "DT", "DT+Treg"))6583 non-expressed genes were removed.
Pre-processing and QC
Pre-processing steps increased the power of the downstream DGE analysis by eliminating majority of unwanted variance that could obscure the true variance caused by the differences in sample conditions. There are several standard steps that are commonly followed to pre-process and QC raw read counts, including:
Checking Library Size
Removal of Undetectable Genes
Normalisation
QC through MDS/PCA
Checking Library Size
A simple pre-processing/QC step is checking the quality of library
size (total number of mapped and quantified reads) for each treatment.
This enable identification of potentially mis-labelled or outlying
samples. This is often visualised through ggplot.
custom_labels <- function(data, y, x) {
exp <- exponent(df = data,y_column = y)
ifelse(x >= 1000 | x<= 0.001 & x!=0, {
l <- x / 10^exp
parse(text=l)
}, format(x, scientific = FALSE))
}
libSize <- ggplot(dge$samples,aes(x = sample, y = lib.size, fill = group)) +
geom_col(width = 0.8) +
geom_hline(aes(yintercept = lib.size), data = . %>% summarise_at(vars(lib.size), mean), linetype = 2) +
scale_y_continuous(expand = expansion(mult = c(0, 0)),
labels = function(x) custom_labels(data = dge$samples, y = "lib.size", x = x)) +
scale_fill_manual(values = groupColour)+
labs(x = "",
title = "Sample Library Size",
y = paste0("Library size (\u00D710", convert_to_superscript(exponent(dge$samples, "lib.size")), ")")) +
coord_flip() +
bossTheme_bar(base_size = 14)
libSize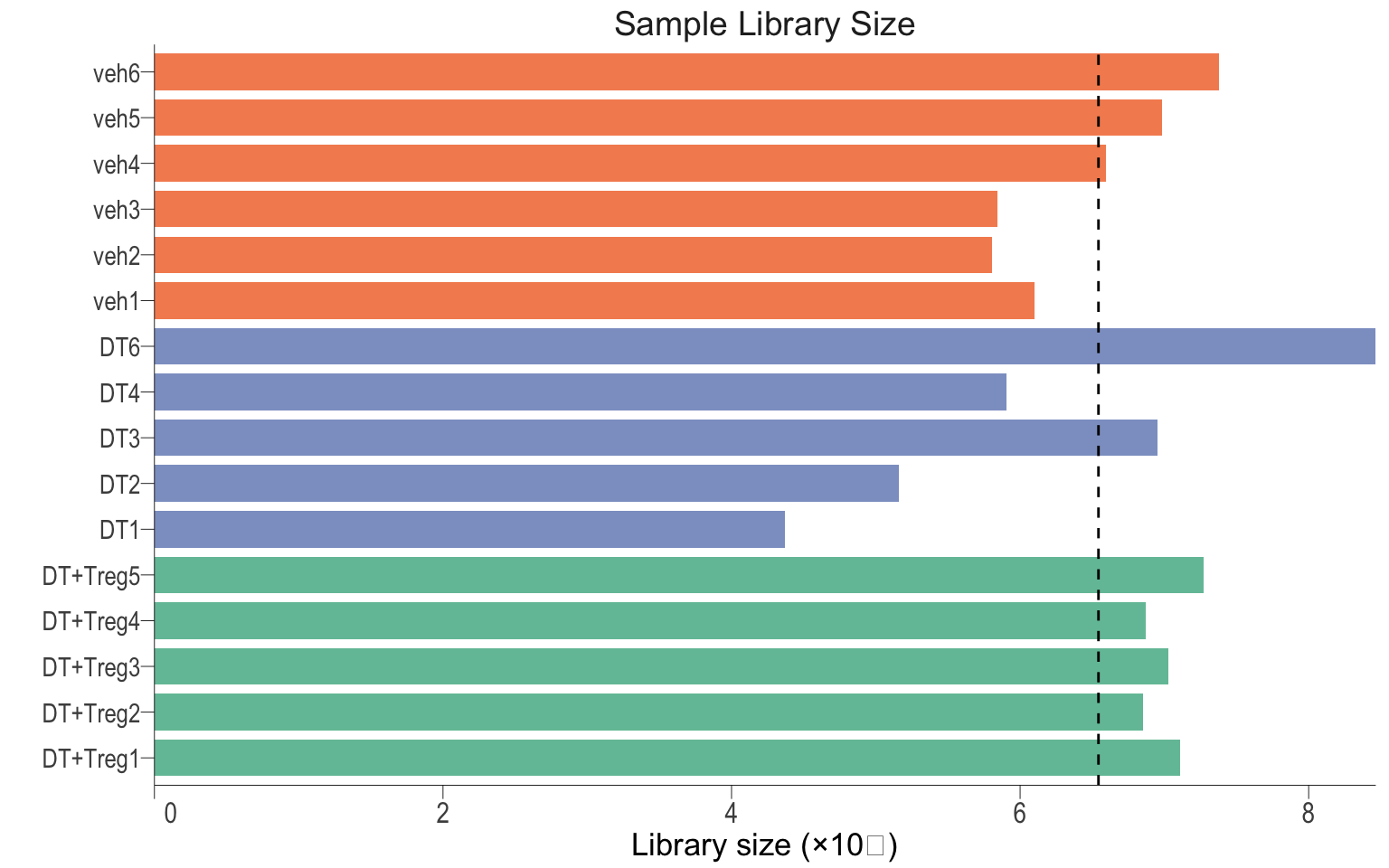
Sample library size. Dash line represent average library size
if(savePlots){
ggsave(here::here("2_plots/1_QC/library_size.svg"),
plot = libSize,
width = 10,
height = 9,
units = "cm")
}NOTE: The library size here is small because “ambiguous” and “no_feature” reads were removed
Removal of Low-Expressed Genes
Filtering out low-expressed genes is a standard pre-processing step in DGE analysis as it can significantly increase the power to differentiate differentially expressed genes by eliminating the variance caused by genes that are lowly expressed in all samples.
The threshold of removal is arbitrary and is often determined after
visualisation of the count distribution. The count distribution can be
illustrated in a density plot through ggplot. A common
metric used to display the count distribution is log Counts per
Million (logCPM)
cpm_filter <- 1.5
beforeFiltering <- dge %>%
edgeR::cpm(log = TRUE) %>%
melt %>%
dplyr::filter(is.finite(value)) %>%
ggplot(aes(x = value,colour = Var2)) +
geom_density() +
labs(title = "Before filtering low-expressed genes",
subtitle = paste0(nrow(dge), " genes"),
x = "logCPM",
y = "Density",
colour = "Sample Groups") +
bossTheme_bar(base_size = 14)
if(savePlots){
ggsave("counts_before_filtering.svg",
plot = beforeFiltering + bossTheme(base_size = 14),
width = 10,
height = 10,
units = "cm",
path = here::here("2_plots/1_QC/"))
}Ideally, the filtering the low-expressed genes should remove the
large peak with logCPM < 0, i.e., remove any genes which
have less than one count per million. A common guideline is to keep all
genes that have > 1-2 cpm in the smallest group on a treatment. In
this case, both groups (WT and KO) have four
replicates.
At CPM > 1, majority of the peak with
logCPM < 0 were removed. This may need adjustments later
as increase genes may also decrease the power of the differential
expression algorithm
To to keep genes that are are more than 1.5 CPM in at least 5
samples. Mathematically this would be identifying genes (rows) with CPM
> 1.5; and identifying total row sum that is
>= 5.
#the genes kept have >2 CPM for at least 4 samples
keptGenes <- (rowSums(cpm(dge) > cpm_filter) >= 5)
afterFiltering <- dge %>%
edgeR::cpm(log = TRUE) %>%
#for var1 (gene names) extract only the keptGenes and discard all other genes in the logCPM data
magrittr::extract(keptGenes, ) %>%
melt %>%
dplyr::filter(is.finite(value)) %>%
ggplot(aes(x = value,colour = Var2)) +
geom_density() +
labs(title = "After filtering low-expressed genes",
subtitle = paste0(table(keptGenes)[[2]], " genes"),
x = "logCPM",
y = "Density",
colour = "Sample Groups") +
bossTheme(base_size = 14,legend = "bottom")
if(savePlots){
ggsave("counts_after_filtering.svg",
plot = afterFiltering + bossTheme(base_size = 14),
width = 10,
height = 10,
units = "cm",
path = here::here("2_plots/1_QC/"))
}
beforeFiltering + afterFiltering + plot_layout(guides = "collect") & bossTheme_bar(base_size = 14,legend = "none")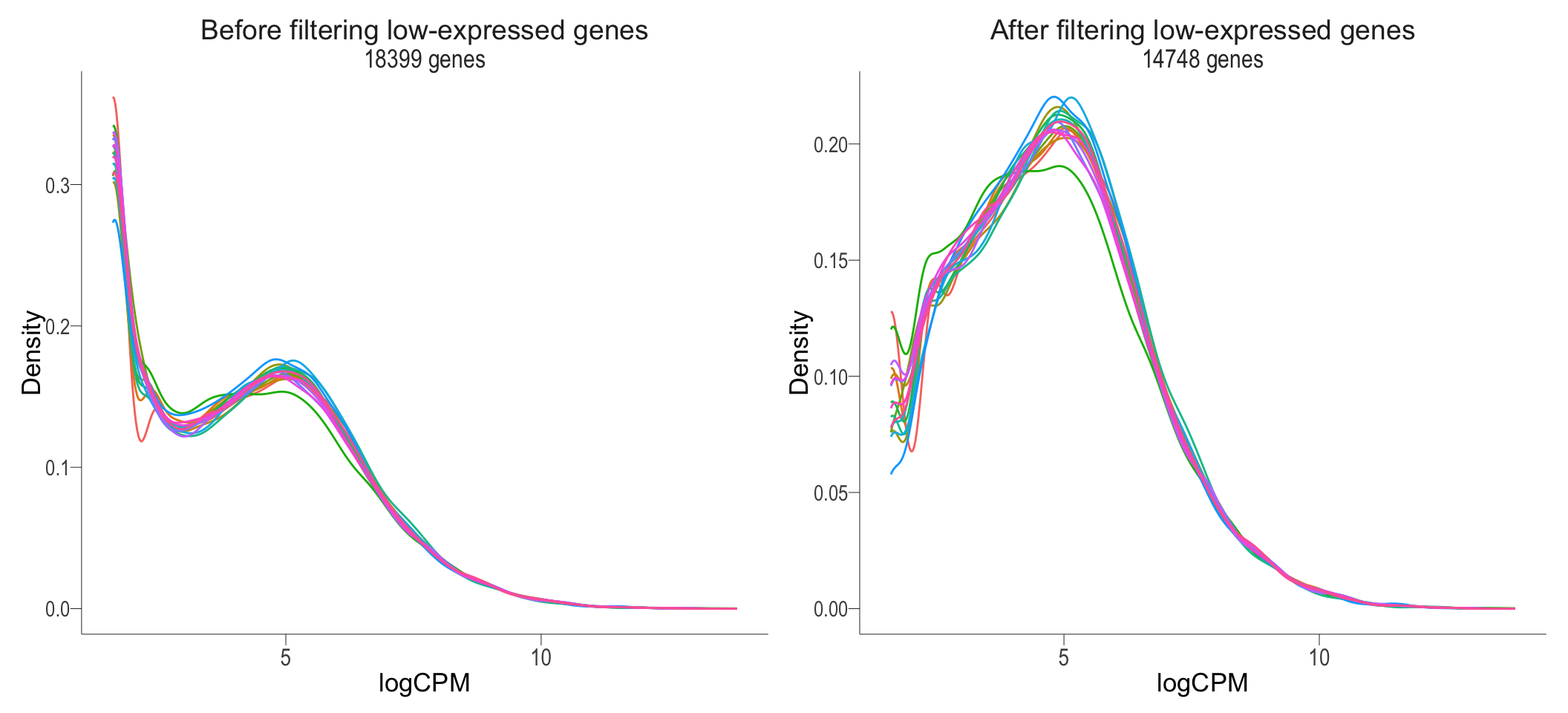
Before and after removal of lowly expressed genes
if(savePlots){
ggsave(filename = "counts_before_after_filtering.svg",
path = here::here("2_plots/1_QC/"),
width = 20,
height = 14,
units = "cm")
}Following the removal of 6583 non-expressed and 3651 low-expressed genes (< 0.5CPM in at least 5 samples), 14748 genes remained for downstream analysis
Subset the DGElist object
After filtering the low-expressed genes, the DGElist object is updated to eliminate the low-expressed genes from future analysis
#extract genes from keptGenes and recalculate the lib size
dge <- dge[keptGenes,,keep.lib.sizes = FALSE]Normalisation
Using the TMM (trimmed mean of M value) method of normalisation
through the edgeR package. The TMM approach creates a
scaling factor as an offset to be supplied to Negative Binomial model.
The calcNormFactors function calculate the normalisation
and return the adjusted norm.factor to the
dge$samples element.
Mean-difference (MD) plots
The following visualisation of the TMM normalisation is plotted using
the mean-difference (MD) plot. The MD plot visualise the library
size-adjusted logFC between two samples (the difference) against the
log-expression across all samples (the mean). In this instance,
sample 1 is used to compare against an artificial library
construct from the average of all the other samples
Ideally, the bulk of gene expression following the TMM normalisation
should be centred around expression log-ratio of 0, which
indicates that library size bias between samples have been successfully
removed. This should be repeated with all the samples in the dge
object.
Before
par(mfrow = c(2, 4), mar = c(2, 2, 1, 1))
for (i in 1:8) {
limma::plotMD(cpm(dge, log = TRUE), column = i)
abline(h = 0, col = "red", lty = 2, lwd = 2)
}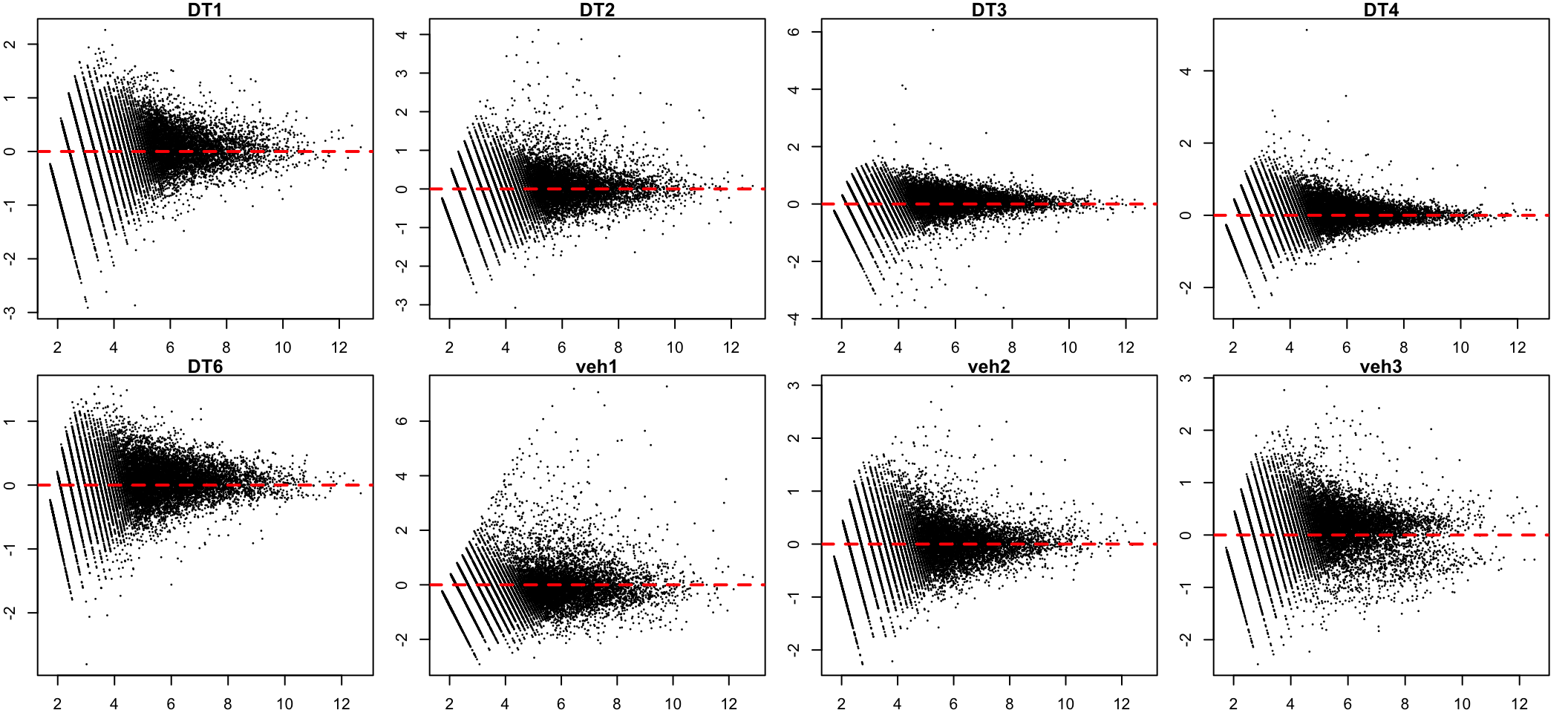
MA plot before TMM normalisation
After
#after normalisation
dge <- edgeR::calcNormFactors(object = dge,
method = "TMM")
par(mfrow = c(2, 4), mar = c(2, 2, 1, 1))
for (i in 1:8) {
limma::plotMD(cpm(dge, log = TRUE), column = i)
abline(h = 0, col = "red", lty = 2, lwd = 2)
}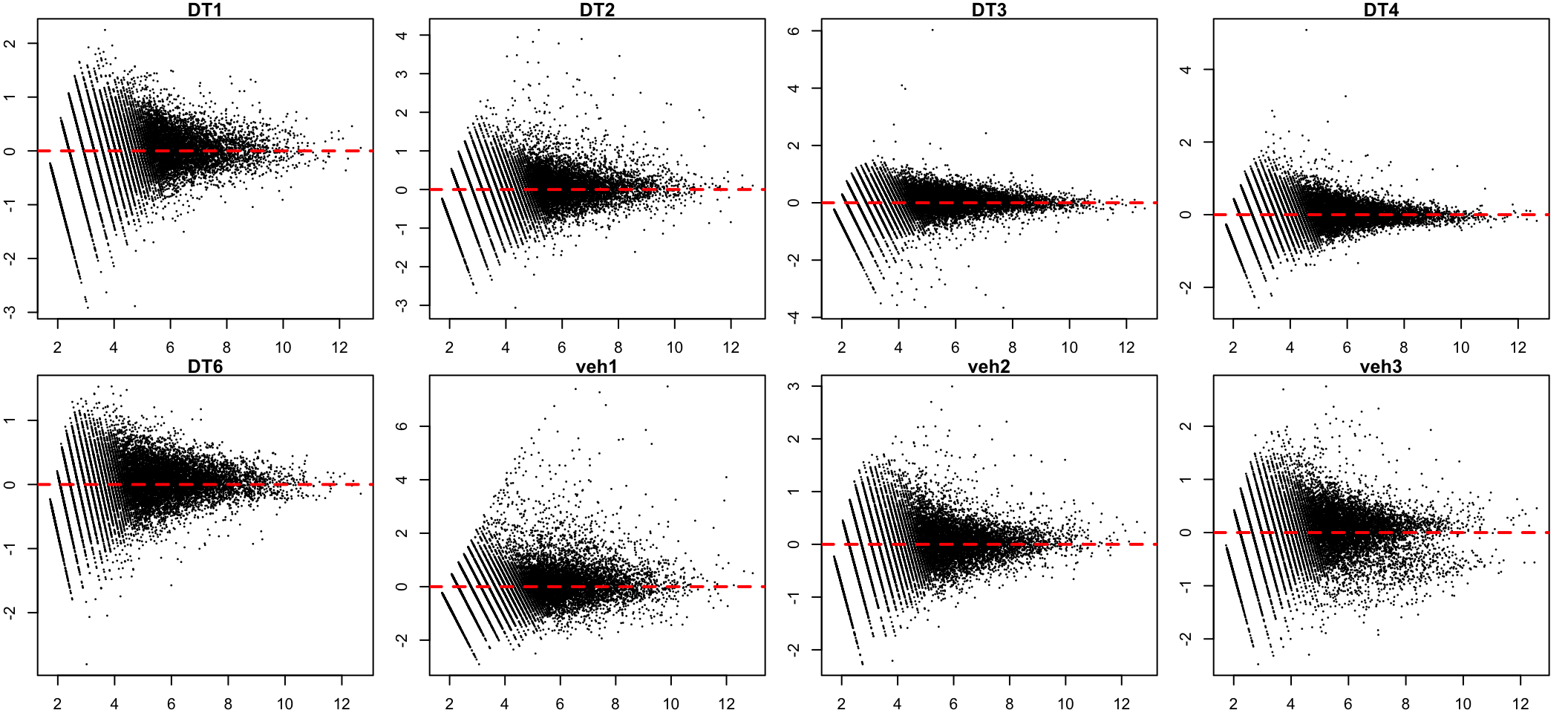
MA plot after TMM normalisation
Normalisation factors
dge$samples %>% DT(.,caption = "Table: Normalised samples")Pinciple Component Analysis (PCA)
Principal Component Analysis (PCA) is a dimensionality reduction technique widely employed to capture the intrinsic patterns and variability within high-dimensional datasets. By transforming the original gene expression data into a set of uncorrelated principal components, PCA helps reveal the major sources of variation in the dataset. This enables assessment of overall similarity between samples
# Perform PCA analysis:
pca_analysis <- prcomp(t(cpm(dge, log = TRUE)))
# Create the plot
pca_2d <- lapply(list(`1_2` = c("PC1", "PC2"),
`1_3` = c("PC1", "PC3"),
`2_3` = c("PC2", "PC3")),
function(i) {
p <- pca_analysis$x %>%
cbind(dge$samples) %>%
as_tibble() %>%
ggplot(aes(x = .data[[i[1]]], y = .data[[i[2]]], colour = group, shape = as.factor(rep))) +
geom_point(size=3) +
scale_color_manual(values = groupColour)+
# scale_shape_manual(values = c(15:21)) +
labs(x = paste0(i[1], " (", percent(summary(pca_analysis)$importance["Proportion of Variance",i[1]]),")"),
y = paste0(i[2], " (", percent(summary(pca_analysis)$importance["Proportion of Variance",i[2]]),")"),
colour = "Groups",
shape = "Replicate") +
bossTheme(base_size = 14,legend = "right")
ggsave(paste0(i[1], "_", i[2],".svg"), plot = p,path = here::here("2_plots/1_QC/"),width = 11, height = 9, units = "cm")
return(p)
})
wrap_plots(pca_2d) + plot_layout(guides = "collect") & bossTheme(base_size = 14,legend = "bottom")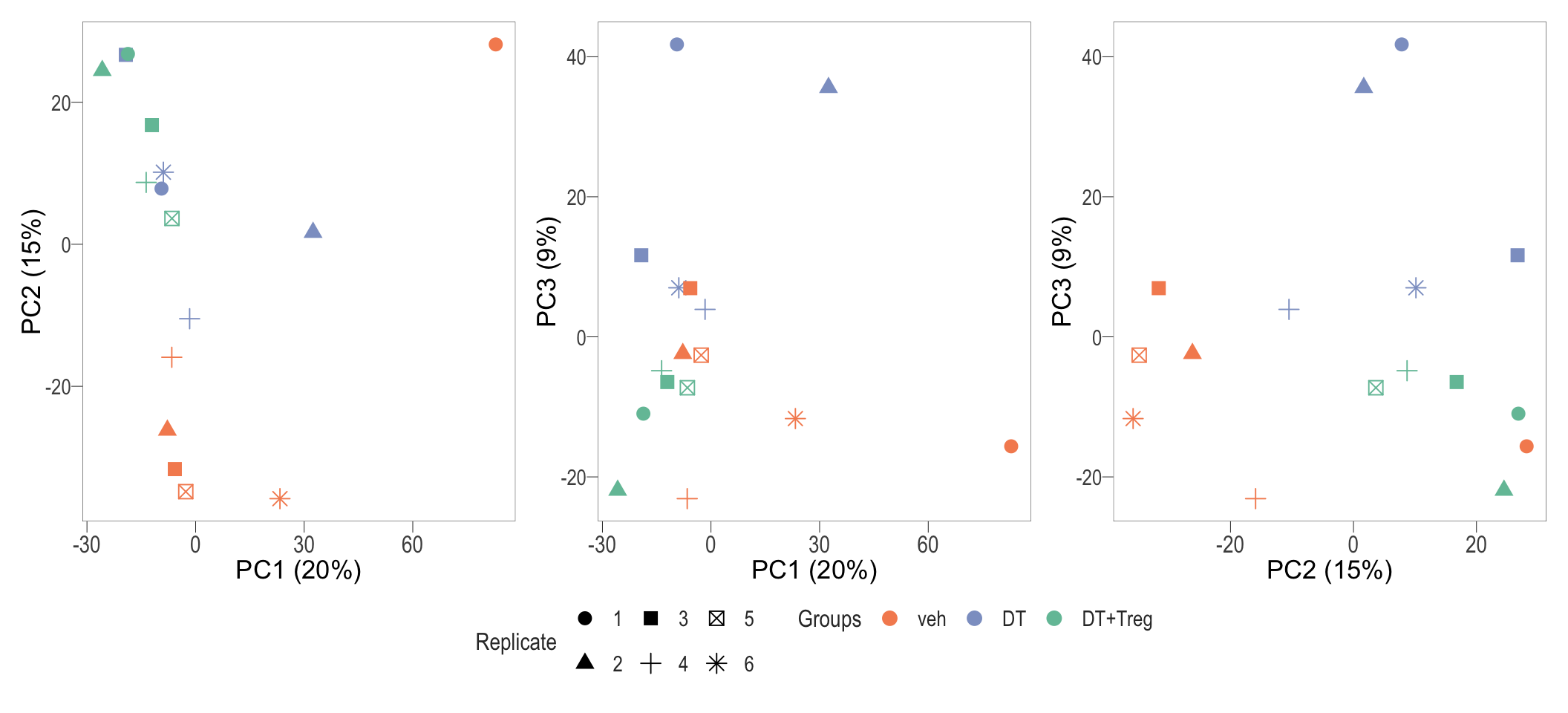
PCA plot
pc <- pca_analysis[["x"]][,1:3] %>% as.data.frame()
pc$PC2 <- -pc$PC2
pc$PC3 <- -pc$PC3
pc = cbind(pc, dge$samples)
totVar <- summary(pca_analysis)[["importance"]]['Proportion of Variance',]
totVar <- 100 * sum(totVar[1:3])
pca_3d <- plot_ly(pc, x = ~PC1, y = ~PC2, z = ~PC3, color = ~dge$samples$group, colors = groupColour,
marker = list(symbol = 'circle', sizemode = 'diameter', size =5),
# sizes = c(5, 70),
# text = ~paste('Term :', term,'<br>P. Term:', parentTerm, '<br>Sig :', score),
hoverinfo = 'text') %>%
layout(showlegend = T,
title = paste0('Total Explained Variance = ', totVar),
scene = list(xaxis = list(title = 'PC 1 (20%)',
gridcolor = 'rgb(194, 197, 204)',
zerolinewidth = 1,
ticklen = 5,
gridwidth = 2),
yaxis = list(title = 'PC 2 (15%)',
gridcolor = 'rgb(194, 197, 204)',
zerolinewidth = 1,
ticklen = 5,
gridwith = 2),
zaxis = list(title = 'PC 3 (9%)',
gridcolor = 'rgb(194, 197, 204)',
zerolinewidth = 1,
ticklen = 5,
gridwith = 2)))
pca_3dCorrelation plot
A correlation matrix between principal components (PC) and metadata is crucial for understanding the relationship between the high-dimensional features represented by principal components and additional information about the samples. This analysis helps identify if and how the PC are related to experimental conditions, sample characteristics, or other relevant factors; thus, enabling assessment of the biological or technical factors driving the observed patterns in the principal components.
Until more metadata is supplied, correlation matrix is unnecessary
corr_plot <- pca_analysis$x %>%
as.data.frame() %>%
rownames_to_column("sampleName") %>%
left_join(samples) %>%
as_tibble() %>%
dplyr::select(
PC1,
PC2,
PC3,
Groups=group,
Mated,
"Library size"=lib.size,
"Normalisation Factor"=norm.factors
) %>%
mutate(Groups = as.numeric(as.factor(Groups))) %>%
cor(method = "spearman") %>%
corrplot(
type = "lower",
diag = FALSE,
addCoef.col = 1, addCoefasPercent = TRUE
)Save DGElist object
# Save DGElist object into the data/R directory
saveRDS(object = dge, file = here::here("0_data/rds_objects/dge.rds"))
sessionInfo()R version 4.4.1 (2024-06-14)
Platform: aarch64-apple-darwin20
Running under: macOS Sonoma 14.5
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Australia/Adelaide
tzcode source: internal
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] extrafont_0.19 Glimma_2.14.0 edgeR_4.2.1
[4] limma_3.60.4 AnnotationHub_3.12.0 BiocFileCache_2.12.0
[7] dbplyr_2.5.0 BiocGenerics_0.50.0 patchwork_1.2.0
[10] plotly_4.10.4 DT_0.33 corrplot_0.92
[13] cowplot_1.1.3 ggrepel_0.9.5.9999 ggbiplot_0.6.2
[16] scales_1.3.0 here_1.0.1 bookdown_0.40
[19] lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1
[22] purrr_1.0.2 tidyr_1.3.1 ggplot2_3.5.1
[25] tidyverse_2.0.0 reshape2_1.4.4 tibble_3.2.1
[28] readr_2.1.5 magrittr_2.0.3 dplyr_1.1.4
loaded via a namespace (and not attached):
[1] rstudioapi_0.16.0 jsonlite_1.8.8
[3] farver_2.1.2 rmarkdown_2.27
[5] fs_1.6.4 zlibbioc_1.50.0
[7] ragg_1.3.2 vctrs_0.6.5
[9] memoise_2.0.1 htmltools_0.5.8.1
[11] S4Arrays_1.4.1 curl_5.2.1
[13] SparseArray_1.4.8 sass_0.4.9
[15] bslib_0.8.0 htmlwidgets_1.6.4
[17] plyr_1.8.9 cachem_1.1.0
[19] whisker_0.4.1 lifecycle_1.0.4
[21] pkgconfig_2.0.3 Matrix_1.7-0
[23] R6_2.5.1 fastmap_1.2.0
[25] GenomeInfoDbData_1.2.12 MatrixGenerics_1.16.0
[27] digest_0.6.36 colorspace_2.1-1
[29] AnnotationDbi_1.66.0 S4Vectors_0.42.1
[31] DESeq2_1.44.0 rprojroot_2.0.4
[33] textshaping_0.4.0 crosstalk_1.2.1
[35] GenomicRanges_1.56.1 RSQLite_2.3.7
[37] filelock_1.0.3 labeling_0.4.3
[39] fansi_1.0.6 timechange_0.3.0
[41] httr_1.4.7 abind_1.4-5
[43] compiler_4.4.1 bit64_4.0.5
[45] withr_3.0.1 BiocParallel_1.38.0
[47] DBI_1.2.3 highr_0.11
[49] Rttf2pt1_1.3.12 rappdirs_0.3.3
[51] DelayedArray_0.30.1 tools_4.4.1
[53] httpuv_1.6.15 extrafontdb_1.0
[55] glue_1.7.0 promises_1.3.0
[57] generics_0.1.3 gtable_0.3.5
[59] tzdb_0.4.0 data.table_1.15.4
[61] hms_1.1.3 utf8_1.2.4
[63] XVector_0.44.0 BiocVersion_3.19.1
[65] pillar_1.9.0 later_1.3.2
[67] lattice_0.22-6 bit_4.0.5
[69] tidyselect_1.2.1 locfit_1.5-9.10
[71] Biostrings_2.72.1 knitr_1.48
[73] git2r_0.33.0 IRanges_2.38.1
[75] SummarizedExperiment_1.34.0 svglite_2.1.3
[77] stats4_4.4.1 xfun_0.46
[79] Biobase_2.64.0 statmod_1.5.0
[81] matrixStats_1.3.0 stringi_1.8.4
[83] UCSC.utils_1.0.0 workflowr_1.7.1
[85] lazyeval_0.2.2 yaml_2.3.10
[87] evaluate_0.24.0 codetools_0.2-20
[89] BiocManager_1.30.23 cli_3.6.3
[91] systemfonts_1.1.0 munsell_0.5.1
[93] jquerylib_0.1.4 Rcpp_1.0.13
[95] GenomeInfoDb_1.40.1 png_0.1-8
[97] parallel_4.4.1 blob_1.2.4
[99] viridisLite_0.4.2 crayon_1.5.3
[101] rlang_1.1.4 KEGGREST_1.44.1