Gene ontology (GO) analysis
Ha M. Tran
08-01-2024
Last updated: 2024-08-02
Checks: 7 0
Knit directory: 5_Treg_uNK/1_analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(12345) was run prior to running the
code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 73ae14f. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Untracked files:
Untracked: .DS_Store
Untracked: .gitignore
Untracked: cellChat.Rmd
Unstaged changes:
Modified: 0_data/rds_plots/deHmap_plots.rds
Modified: 0_data/rds_plots/go_combined_parTerm_dotPlot.rds
Modified: 0_data/rds_plots/go_parTerm_dotPlot.rds
Modified: 0_data/rds_plots/kegg_path_Hmap.rds
Deleted: 1_analysis/cellChat.Rmd
Modified: 3_output/GO_sig.xlsx
Modified: 3_output/KEGG_all.xlsx
Modified: 3_output/KEGG_sig.xlsx
Modified: 3_output/de_genes_all.xlsx
Modified: 3_output/de_genes_sig.xlsx
Modified: 3_output/reactome_all.xlsx
Modified: 3_output/reactome_sig.xlsx
Modified: sampleHeatmap.rds
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (1_analysis/go.Rmd) and HTML
(docs/go.html) files. If you’ve configured a remote Git
repository (see ?wflow_git_remote), click on the hyperlinks
in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 73ae14f | Ha Tran | 2024-08-02 | Large update with final visualisations |
| html | 73ae14f | Ha Tran | 2024-08-02 | Large update with final visualisations |
| Rmd | a5cdd4e | git | 2024-03-25 | switching os |
| Rmd | d0ea132 | Ha Manh Tran | 2024-02-15 | windows crashed |
| html | e9e7671 | tranmanhha135 | 2024-02-08 | Build site. |
| Rmd | 8da2e31 | tranmanhha135 | 2024-02-08 | workflowr::wflow_publish(here::here("1_analysis/*.Rmd")) |
| html | 36aeb85 | Ha Manh Tran | 2024-01-13 | Build site. |
| Rmd | c78dfac | tranmanhha135 | 2024-01-12 | remote from ipad |
| html | c78dfac | tranmanhha135 | 2024-01-12 | remote from ipad |
| Rmd | 8ce4e15 | tranmanhha135 | 2024-01-10 | minor adjustments |
| Rmd | 221e2fa | tranmanhha135 | 2024-01-10 | fixed error |
| html | 221e2fa | tranmanhha135 | 2024-01-10 | fixed error |
| html | 762020e | tranmanhha135 | 2024-01-09 | Build site. |
| Rmd | c6d389f | tranmanhha135 | 2024-01-09 | workflowr::wflow_publish(here::here("1_analysis/*.Rmd")) |
| Rmd | 05fa0b3 | tranmanhha135 | 2024-01-06 | added description |
# working with data
library(dplyr)
library(magrittr)
library(readr)
library(tibble)
library(reshape2)
library(tidyverse)
# Visualisation:
library(kableExtra)
library(ggplot2)
library(grid)
library(DT)
library(extrafont)
library(VennDiagram)
# Custom ggplot
library(gridExtra)
library(ggbiplot)
library(ggrepel)
library(rrvgo)
library(d3treeR)
library(plotly)
library(GOSemSim)
library(data.table)
# Bioconductor packages:
library(edgeR)
library(limma)
library(Glimma)
library(clusterProfiler)
library(org.Mm.eg.db)
library(enrichplot)
library(patchwork)
library(pandoc)
library(knitr)# load DGElist previously created in the set up
dge <- readRDS(here::here("0_data/rds_objects/dge.rds"))
lm <- readRDS(here::here("0_data/rds_objects/lm.rds"))
lm_all <- readRDS(here::here("0_data/rds_objects/lm_all.rds"))
lm_sig <- readRDS(here::here("0_data/rds_objects/lm_sig.rds"))
Comp <- readRDS(here::here("0_data/rds_objects/comp.rds"))
Ont <- c("BP","MF","CC")
# to increase the knitting speed. change to T to save all plots
savePlots <- T
export <- T# Theme
bossTheme <- readRDS(here::here("0_data/functions/bossTheme.rds"))
bossTheme_bar <- readRDS(here::here("0_data/functions/bossTheme_bar.rds"))
groupColour <- readRDS(here::here("0_data/functions/groupColour.rds"))
groupColour_dark <- readRDS(here::here("0_data/functions/groupColour_dark.rds"))
expressionCol <- readRDS(here::here("0_data/functions/expressionCol.rds"))
expressionCol_dark <- readRDS(here::here("0_data/functions/expressionCol_dark.rds"))
compColour <- readRDS(here::here("0_data/functions/compColour.rds"))
DT <- readRDS(here::here("0_data/functions/DT.rds"))
# Plotting
convert_to_superscript <- readRDS(here::here("0_data/functions/convert_to_superscript.rds"))
exponent <- readRDS(here::here("0_data/functions/exponent.rds"))
format_y_axis <- readRDS(here::here("0_data/functions/format_y_axis.rds"))
firstCap <- function(x) {
substr(x, 1, 1) <- toupper(substr(x, 1, 1))
x
}Gene ontology (GO) Analysis
Functional enrichment analysis is a method used to identify biological functions or processes overrepresented in a set of genes or proteins.
Gene Ontology (GO) is a standardized system for annotating genes and their products with terms from a controlled vocabulary, organized into three main categories: Molecular Function, Biological Process, and Cellular Component.
Biological Process (BP): Describes the larger, coordinated biological events or processes in which a gene product is involved. This category represents a series of molecular events that contribute to a specific function.
Molecular Function (MF): Describes the specific molecular activities that a gene product performs, such as catalytic or binding activities.
Cellular Component (CC): Describes the location or structure within the cell where a gene product is active, such as the nucleus, cytoplasm, or membrane.
Each of these three main categories is further organized into a hierarchical structure with more specific terms. The terms become more specialized as you move down the hierarchy (ontology level). Comparing a gene list to a reference database offers critical insights into the biological significance of gene expression changes.
# circumvent rerunning of lengthy analysis.
enrichGO <- readRDS(here::here("0_data/rds_objects/enrichGO.rds"))
enrichGO_sig <- readRDS(here::here("0_data/rds_objects/enrichGO_sig.rds"))# `goSummaries` is a package created by Dr Stevie Pederson for filtering GO terms based on ontology level.
goSummaries <- url("https://uofabioinformaticshub.github.io/summaries2GO/data/goSummaries.RDS") %>%
readRDS()
minPath <- 3
mmGO <- lapply(c("BP","MF","CC"), function(ont){godata('org.Mm.eg.db', ont=ont)}) %>% setNames(c("BP","MF","CC"))
enrichGO=list()
enrichGO_sig <- list()
for (comp in Comp) {
# find enriched GO terms
enrichGO[[comp]] <- clusterProfiler::enrichGO(
gene =lm_sig[[comp]]$entrezid,
universe = lm_all[[comp]]$entrezid,
OrgDb = org.Mm.eg.db,
keyType = "ENTREZID",
ont = "ALL",
pAdjustMethod = "fdr",
pvalueCutoff = 0.05
)
enrichGO[[comp]] <- pairwise_termsim(enrichGO[[comp]], method = "Wang",semData = mmGO[[1]], showCategory = nrow(enrichGO[[comp]]@result))
}
for (comp in Comp) {
# bind to goSummaries to elminate go terms with ontology levels 1 and 2.
enrichGO_sig[[comp]] <- enrichGO[[comp]] %>%
clusterProfiler::setReadable(OrgDb = org.Mm.eg.db, keyType = "auto")
enrichGO_sig[[comp]] <- enrichGO_sig[[comp]] %>%
as.data.frame() %>%
rownames_to_column("id") %>%
left_join(goSummaries) %>%
# dplyr::filter(shortest_path >= minPath) %>%
column_to_rownames("id")
# adjust go results, separate compound column, add FDR column, adjust the GeneRatio column
enrichGO_sig[[comp]] <- enrichGO_sig[[comp]] %>%
separate(col = BgRatio, sep = "/", into = c("Total", "Universe")) %>%
dplyr::mutate(
logFDR = -log(p.adjust, 10),
GeneRatio = Count / as.numeric(Total))
# %>%
# dplyr::select(c("Description", "ontology", "GeneRatio", "pvalue", "p.adjust", "logFDR", "qvalue", "geneID", "Count"))
enrichGO_sig[[comp]]$Description <- enrichGO_sig[[comp]]$Description %>% firstCap() %>% str_wrap(width = 45)
}
saveRDS(object = enrichGO_sig,file = here::here("0_data/rds_objects/enrichGO_sig.rds"))
saveRDS(object = enrichGO,file = here::here("0_data/rds_objects/enrichGO.rds"))simMatrix <- list()
scores <- list()
reducedTerms <- list()
for(ont in Ont) {
simMatrix[[ont]] <- lapply(Comp, function(comp) {
calculateSimMatrix(enrichGO[[comp]]@result$ID,
orgdb="org.Mm.eg.db",
ont=ont,
method="Wang",
semdata = mmGO[[ont]])
}) %>% setNames(Comp)
scores[[ont]] <- lapply(enrichGO, function(x) {setNames(-log10(x@result$p.adjust), x@result$ID)}) %>% setNames(names(enrichGO))
reducedTerms[[ont]] <- lapply(Comp, function(comp) {
reduced_tb <- reduceSimMatrix(simMatrix[[ont]][[comp]],
scores[[ont]][[comp]],
threshold=0.7,
orgdb="org.Mm.eg.db")
reduced_tb$parentTerm <- reduced_tb$parentTerm %>% firstCap() %>% str_wrap(width = 45)
reduced_tb$term <- reduced_tb$term %>% firstCap() %>% str_wrap(width = 35)
return(reduced_tb)
}) %>% setNames(Comp)
}
semSim_df <- list()
reduced_semSim_df <- list()
for(ont in Ont) {
for (comp in Comp) {
subset_df <- subset(reducedTerms[[ont]][[comp]], parent == rownames(reducedTerms[[ont]][[comp]]))
parentTerm_size <- reducedTerms[[ont]][[comp]]$parentTerm %>% as.factor() %>% summary(500)
semSim_df[[ont]][[comp]] <- cbind(subset_df, parentTerm_size)
}
reduced_semSim_df[[ont]] <- as.data.frame(do.call(rbind, semSim_df[[ont]])) %>%
rownames_to_column("comparison")
reduced_semSim_df[[ont]]$comparison <- gsub(pattern = "\\..*", "", reduced_semSim_df[[ont]]$comparison) %>% as.factor()
}
reducedTerms_all <- as.data.frame(do.call(rbind, reduced_semSim_df)) %>%
rownames_to_column("ont")
reducedTerms_all$ont <- gsub(pattern = "\\..*", "", reducedTerms_all$ont) %>% as.factor()
saveRDS(simMatrix, here::here("0_data/rds_objects/simMatrix_ora.rds"))
saveRDS(scores, here::here("0_data/rds_objects/scores_ora.rds"))
saveRDS(reducedTerms, here::here("0_data/rds_objects/reducedTerms_ora.rds"))
saveRDS(semSim_df, here::here("0_data/rds_objects/semSim_df.rds"))
saveRDS(reduced_semSim_df, here::here("0_data/rds_objects/reduced_semSim_df.rds"))
saveRDS(reducedTerms_all, here::here("0_data/rds_objects/reducedTerms_all.rds"))Visualisations
The following visualisations are GO enrichment analysis performed with set of DE genes significantly below FDR 0.1 without FC threshold (TREAT). IMPORTANTLY, these GO terms are all significantly enriched (FDR <0.05)
Dot plot: illustrates the top 25 enriched GO terms.
- \(Gene ratio =\) the number of significant DE gene in the term / the total of number of genes in the term. Indicated by the size
- The shapes represents the three main GO categories, either BP, MP, or CC
Table: list of all the significant GO terms
Upset: illustrate the overlap of gene between different functional terms
Semantic similarity plots - GO specific
Due to the hierarchical structure of Gene Ontologies, the enriched sets generated often exhibit redundancy and pose challenges in interpretation. The subsequent analyses and visualizations seek to alleviate this redundancy in GO sets by grouping comparable terms based on their semantic similarity. The underlying concept behind measuring semantic similarity is grounded in the idea that genes sharing similar functions should possess analogous annotation vocabulary and exhibit close relationships within the ontology structure.
NOTE: the following semantic similarity analyses are performed using Graph-based method (Wang et al. 2007)
Dendrogram plot: performs hierarchical clustering on the semantic similarity of GO terms.
- NOTE: to maintain readability, only the top 50 most significant GO terms are clustered. These clusters are then divided into 9 clades and labeled using the top 4 high-frequency words.
Scatter plot: illustrates the UMAP space between semantically similar significant GO terms
- Distances represent the similarity between terms,
- Size represents the significance (in \(-\log_{10}FDR\)))
- NOTE: to maintain reability, only the top 15 most significant parent terms are labeled. Parent terms are the most significant term in a particular cluster
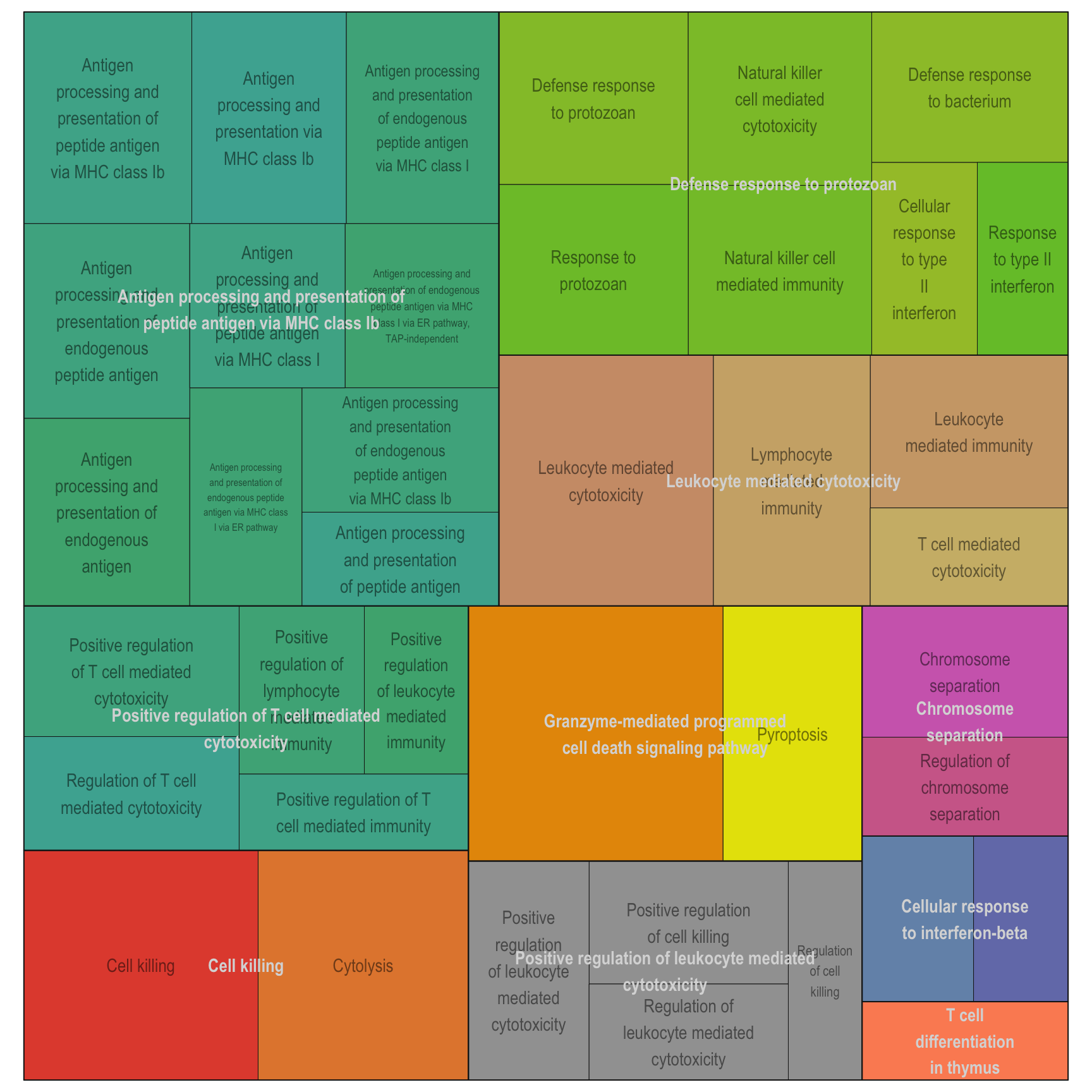
Treemap plot: Visualise the of hierarchical structures of semantically similar GO terms.
- The terms are colored based on their parent term,
- The size of the term is proportional to the significance.
I recommend reading through the full list of significant GO terms and selecting the most biologically relevant for better visualisation
DT vs veh
Dot plot
dot <- list()
tab <- list()
upset <- list()
for (comp in Comp) {
dot[[comp]] <- ggplot(enrichGO_sig[[comp]][1:20, ]) +
geom_point(aes(x = GeneRatio, y = reorder(Description, GeneRatio), colour = logFDR, size = Count, shape = ontology %>% as.factor())) +
scale_color_gradientn(colors = rev(c("#FB8072","#FDB462","#8DD3C7","#80B1D3")),
values = scales::rescale(c(min(enrichGO_sig[[comp]]$logFDR), max(enrichGO_sig[[comp]]$logFDR))),
breaks = scales::pretty_breaks(n = 5)) +
scale_size(range = c(2,5)) +
labs(x = "Gene ratio", y = "", color = expression("-log"[10] * "FDR"), size = "Gene Counts", shape = "Ontology")+
bossTheme(base_size = 14,legend = "right")
tab[[comp]] <- enrichGO_sig[[comp]] %>%
dplyr::mutate_if(is.numeric, funs(as.character(signif(.,3)))) %>%
DT(., caption = "Significantly enriched GO terms")
upset[[comp]] <- upsetplot(x = enrichGO[[comp]], 10)
if(savePlots == TRUE) {
ggsave(filename = paste0("dot_", comp, ".svg"), plot = dot[[comp]], path = here::here("2_plots/3_FA/go/"),
width = 18, height = 20, units = "cm")
ggsave(filename = paste0("upset_", comp, ".svg"), plot = upset[[comp]], path = here::here("2_plots/3_FA/go/"), width = 20, height = 14, units = "cm")
}
}
saveRDS(dot, here::here("0_data/rds_plots/go_dotPlot.rds"))
dot[[1]]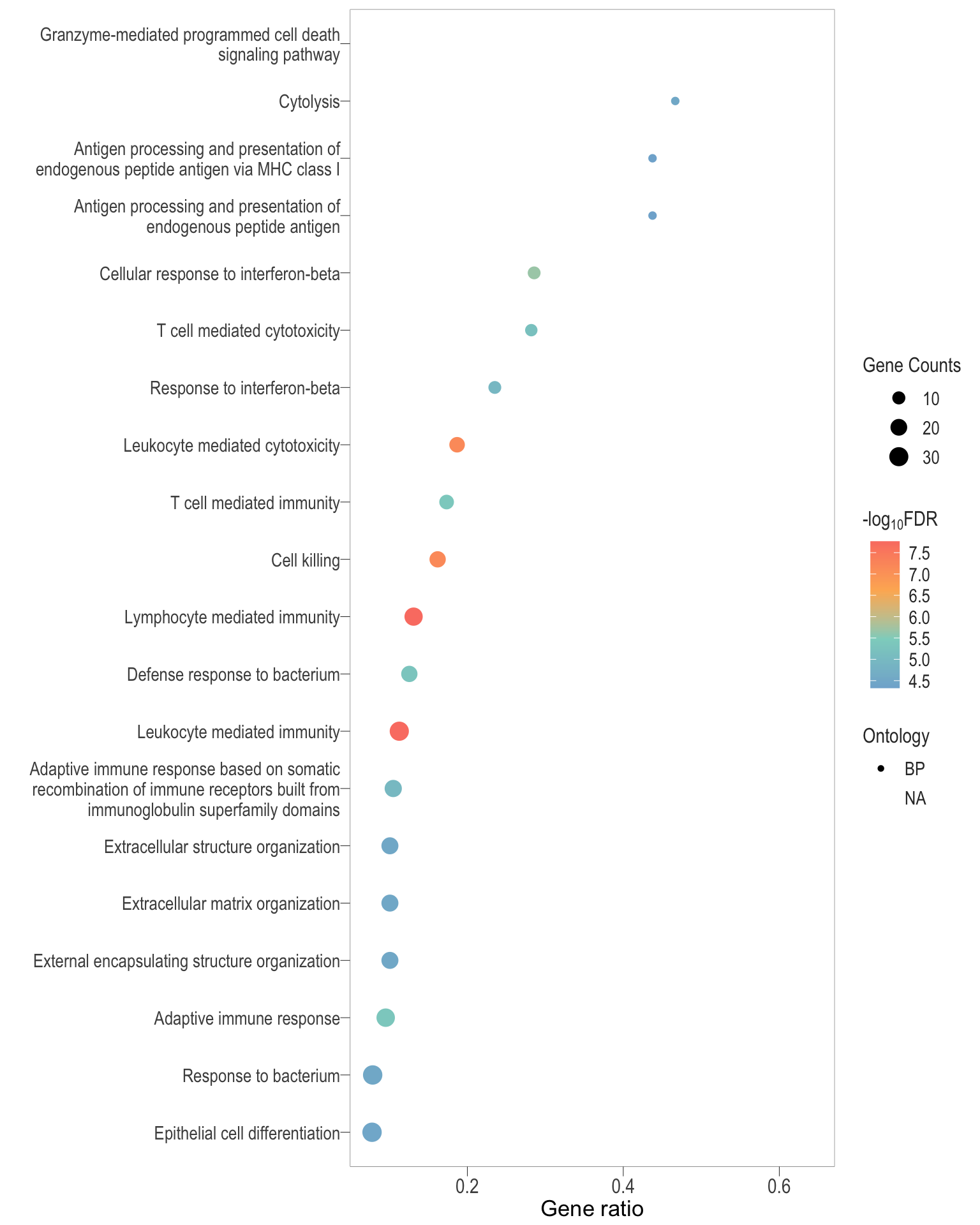
Table
tab[[1]]Upset plot
upset[[1]]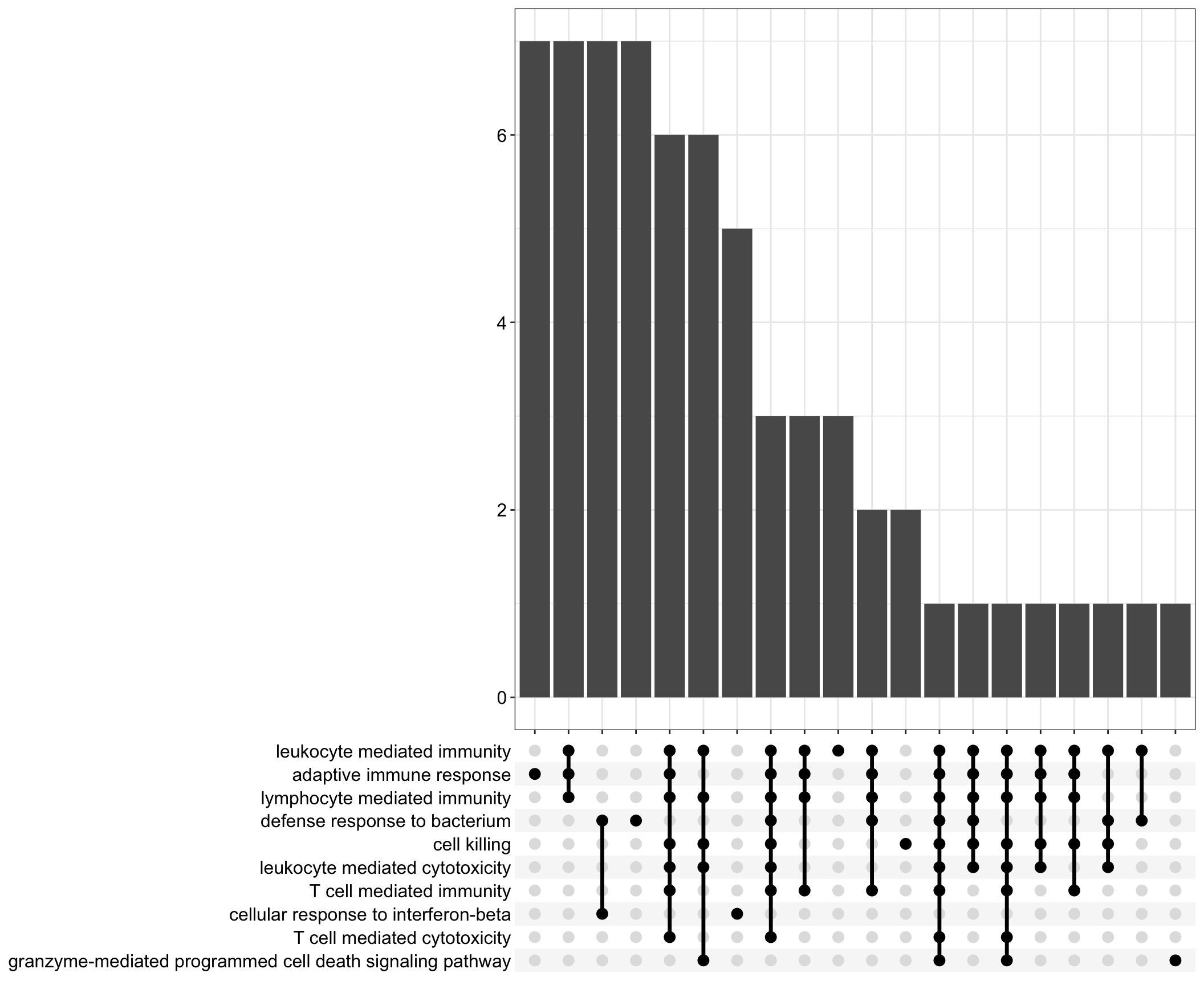
Dendrogram
den <- lapply(enrichGO, function(x) {
treeplot(x,showCategory = 50, fontsize = 3, cex_category = 0.5,
cluster.params = list(method = "ward.D", n = 9, label_words_n = 4, label_format = 30),
hilight.params = list(hilight = F, align = "both"),
clusterPanel.params = list(clusterPanel = "heatMap", pie = "equal", legend_n = 3),
offset.params = list(bar_tree = rel(3), tiplab = rel(4), extend = 0.1, hexpand = 0.4)) +
theme(legend.position = "bottom")
}) %>% setNames(enrichGO)
# saveRDS(den, here::here("0_data/rds_objects/ora_dendrogram.rds"))
# den <- readRDS(here::here("0_data/rds_objects/ora_dendrogram.rds"))
den[[1]]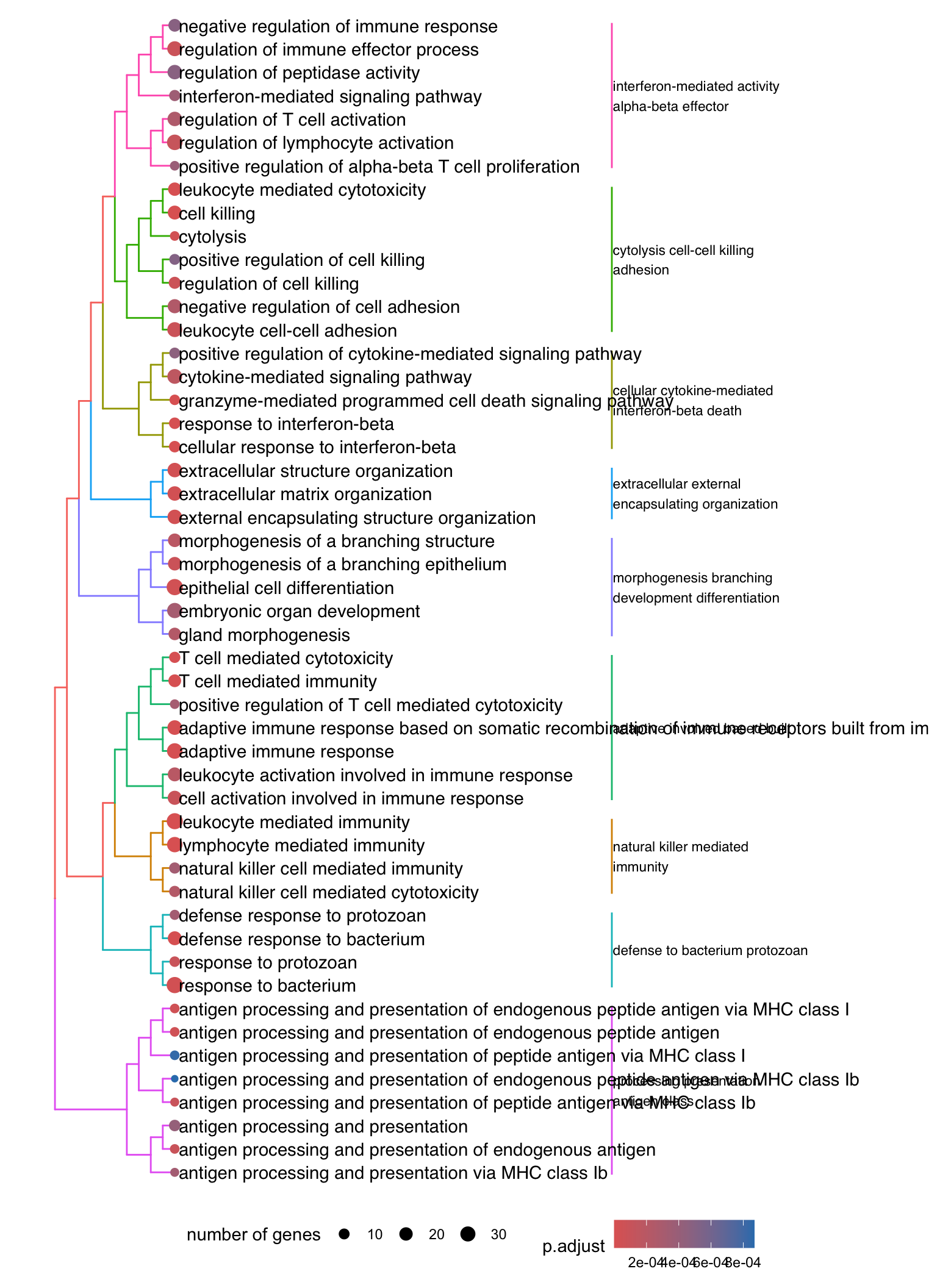
for(i in 1:length(Comp)){
if(savePlots == TRUE) {
ggsave(filename = paste0("semSim_dendrogram_", Comp[i], ".svg"), plot = den[[i]], path = here::here("2_plots/3_FA/go/"),
width = 20, height = 25, units = "cm")
}
}Scatter plot
simMatrix <- readRDS(here::here("0_data/rds_objects/simMatrix_ora.rds"))
scores <- readRDS(here::here("0_data/rds_objects/scores_ora.rds"))
reducedTerms <- readRDS(here::here("0_data/rds_objects/reducedTerms_ora.rds"))
revigo_dimReduction <- function(simMatrix, reducedTerms, algorithm = c("pca", "umap"), size = "score") {
x <- switch(match.arg(algorithm), pca = cmdscale(as.matrix(as.dist(1 - simMatrix)), eig = TRUE, k = 3)$points, umap = umap::umap(as.matrix(as.dist(1 - simMatrix)),n_components = 3)$layout)
df <- cbind(as.data.frame(x), reducedTerms[match(rownames(x), reducedTerms$go), c("term", "parent", "parentTerm", size)])
return(df)
}
dimReduced <- list()
scatter <- list()
for (comp in Comp){
set.seed(3)
dimReduced[[comp]] <- revigo_dimReduction(simMatrix[["BP"]][[comp]], reducedTerms[["BP"]][[comp]], algorithm = "umap")
m <- subset(dimReduced[[comp]], parent == rownames(dimReduced[[comp]]))[1:10,]
scatter[[comp]] <- ggplot(dimReduced[[comp]], aes(x = V1, y = V2, color = parentTerm)) +
geom_point(aes_string(size = "score"), alpha = 0.5, stroke = 0) +
scale_color_discrete(guide = "none") +
# scale_fill_discrete(guide = "none") +
scale_size_continuous(name = expression("-log"[10] * "FDR"), range = c(0,12)) +
scale_x_continuous(name = "UMAP1") +
scale_y_continuous(name = "UMAP2") +
guides(x = ggh4x::guide_axis_truncated(trunc_lower = unit(0, "npc"),trunc_upper = unit(3, "cm")),
y = ggh4x::guide_axis_truncated(trunc_lower = unit(0, "npc"),trunc_upper = unit(3, "cm"))) +
geom_label_repel(aes(label = m$parentTerm),data = m, box.padding = grid::unit(1,"lines"), size = 3, label.size = 0.15) +
bossTheme(14) +
theme(
line = element_blank(),
rect = element_blank(),
panel.border = element_blank(),
axis.text.x = element_blank(),
axis.text.y = element_blank(),
axis.ticks = element_blank(),
legend.position = "right",
axis.line = element_line(arrow = arrow()),
axis.title = element_text(hjust = 0),
axis.title.y = element_text(
family = "Arial Narrow",
face = "plain",
size = 13,
angle = 90,
vjust = 1
),
axis.title.x = element_text(
family = "Arial Narrow",
face = "plain",
size = 13,
angle = 0,
vjust = 0
)
)
if(savePlots == TRUE) {
ggsave(filename = paste0("semSim_scatter_", comp, ".svg"), plot = scatter[[comp]], path = here::here("2_plots/3_FA/go/"),
width = 18, height = 18, units = "cm")
}
}
saveRDS(scatter, here::here("0_data/rds_plots/go_parTerm_scatter.rds"))
scatter[[1]]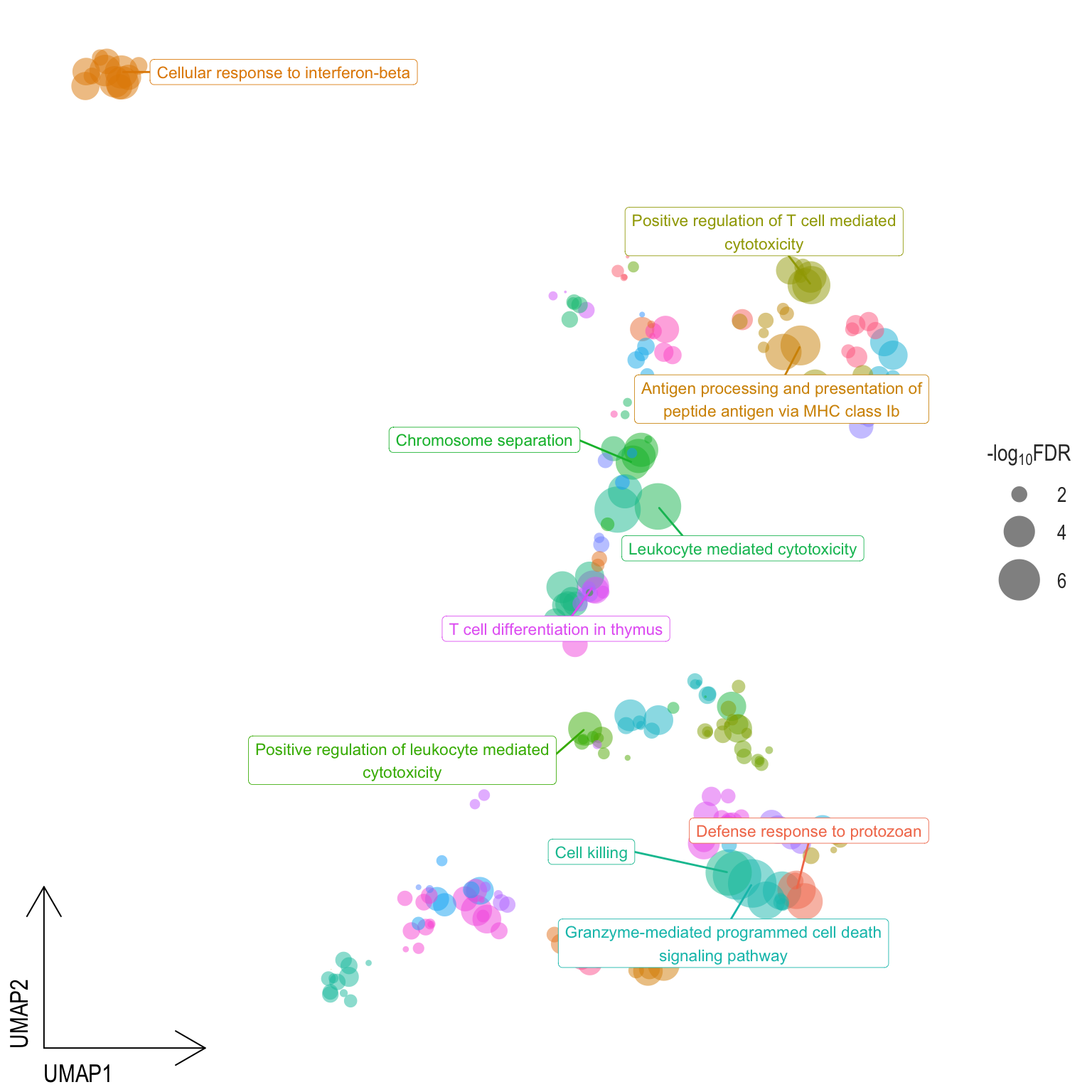
Interactive scatter
scatter_plotly <- list()
for (comp in Comp){
scatter_plotly[[comp]] <- ggplotly(scatter[[comp]] + bossTheme(14)) %>% add_markers(size = 5) %>% layout(showlegend = FALSE)
}
scatter_plotly[[1]]3D Interactive scatter
scatter_3d <- list()
for(comp in Comp){
scatter_3d[[comp]] <- plot_ly(dimReduced[[comp]], x = ~ V1, y = ~ V2, z = ~ V3, color = ~ parentTerm, size = ~ score,
marker = list(symbol = 'circle', sizemode = 'diameter'),
sizes = c(5, 70),
text = ~paste('Term :', term,'<br>P. Term:', parentTerm, '<br>Sig :', score),
hoverinfo = 'text') %>%
layout(showlegend = FALSE,
title = 'Semantically similar GO terms',
scene = list(xaxis = list(title = 'UMAP 1',
gridcolor = 'rgb(255, 255, 255)',
zerolinewidth = 1,
ticklen = 5,
gridwidth = 2),
yaxis = list(title = 'UMAP 2',
gridcolor = 'rgb(255, 255, 255)',
zerolinewidth = 1,
ticklen = 5,
gridwith = 2),
zaxis = list(title = 'UMAP 3',
gridcolor = 'rgb(255, 255, 255)',
zerolinewidth = 1,
ticklen = 5,
gridwith = 2)))
}
scatter_3d[[1]]Parent terms
semSim_df <- readRDS(here::here("0_data/rds_objects/semSim_df.rds"))
semSim_dot <- lapply(Comp, function(comp){
df <- semSim_df[["BP"]][[comp]]
df$parentTerm <- df$parentTerm %>% str_wrap(50)
plot <- ggplot(df) +
geom_point(aes(x = parentTerm_size, y = reorder(parentTerm, score), colour = score, size = parentTerm_size)) +
scale_color_gradientn(colors = rev(c("#FB8072","#FDB462","#8DD3C7","#80B1D3")),
values = scales::rescale(c(min(df$score), max(df$score))),
breaks = scales::pretty_breaks(n = 5)) +
scale_size(range = c(2,5), guide = F) +
labs(x = "Term size", y = "", color = expression("-log"[10] * "FDR"))+
bossTheme(base_size = 14,legend = "right")
if(savePlots == TRUE) {
ggsave(filename = paste0("parTerm_dot_", comp, ".svg"), plot = plot, path = here::here("2_plots/3_FA/go/"),
width = 18, height = 20, units = "cm")
}
return(plot)
})
saveRDS(semSim_dot, here::here("0_data/rds_plots/go_parTerm_dotPlot.rds"))
semSim_dot[1][[1]]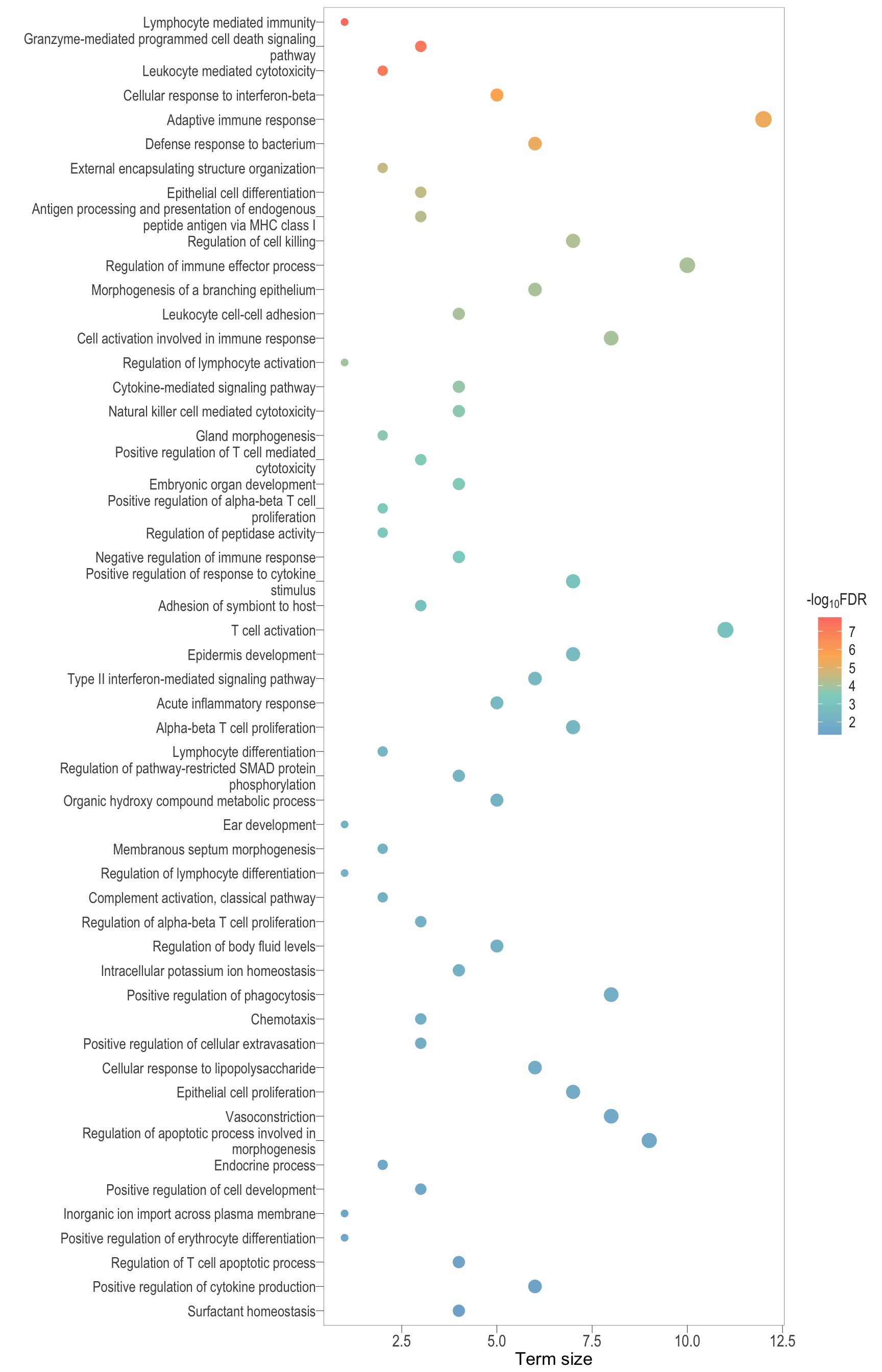
Treemap plot
adjTreemap <- function (x, size = "score", title = "", ...) {
treemap::treemap(
x,
index = c("parentTerm", "term"),
vSize = size,
type = "index",
title = title,
palette = "Set2",
fontcolor.labels = c("grey85","#00000080"),
bg.labels = 0,
border.col = "grey10",
border.lwds = c(1,0.5),
fontfamily.labels = "Arial Narrow"
)
}
adjTreemap(reducedTerms[[1]][[1]])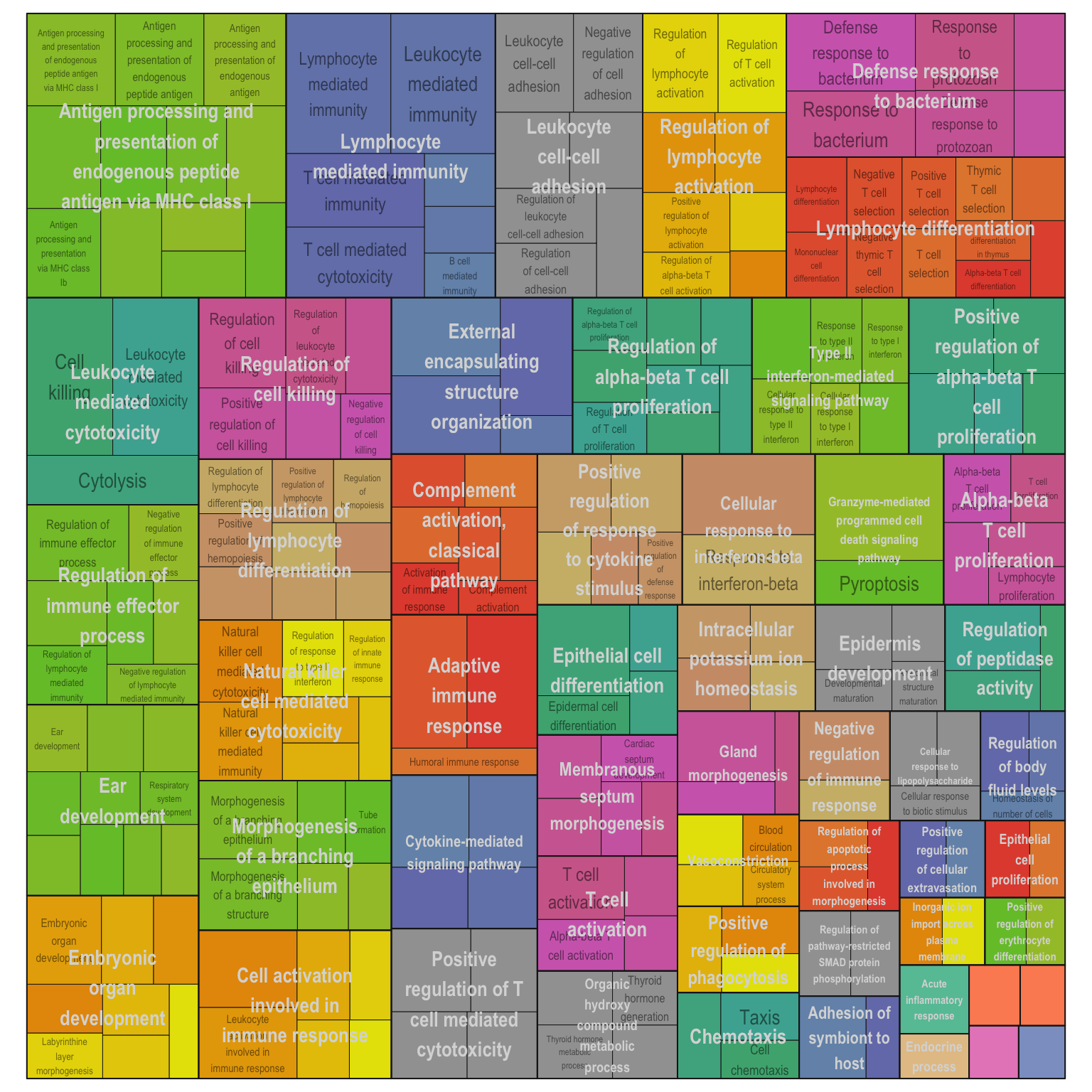
Interactive Tree
# png(filename=here::here("2_plots/tree.png"),width=20, height=20,units = "cm",res = 900)
# tree <- adjTreemap(reducedTerms)
# dev.off()
library(htmltools)
interactive_treemap <- function(x){
browsable(
tagList(
tags$head(
tags$style('text.label{font-size: 20px !important}')
),
d3tree3(adjTreemap(x), rootname = "General")
)
)
}
interactive_treemap(reducedTerms[[1]][[1]])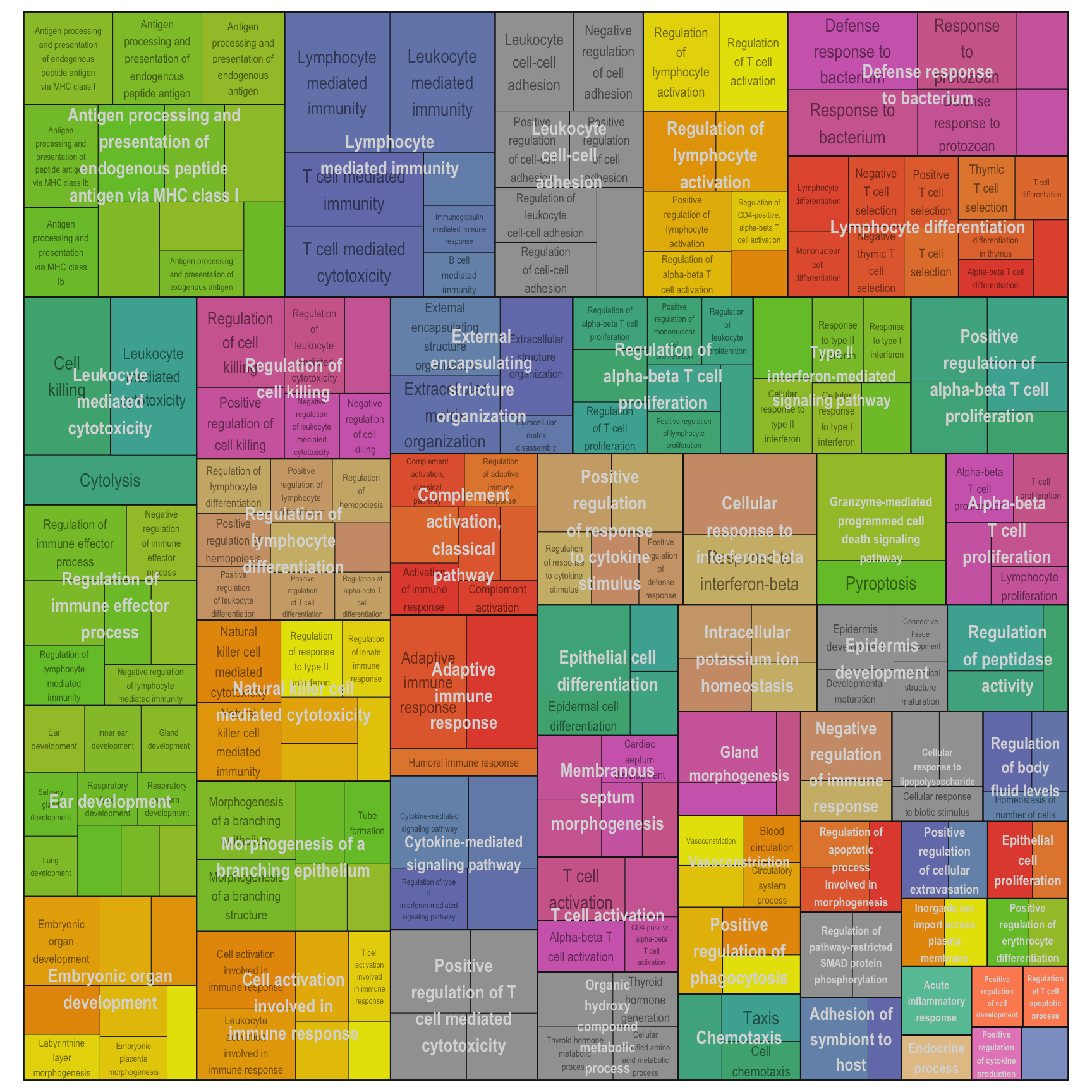
## this function is basically creating chunks within chunks, and then
## I use results='asis' so that the html image code is rendered
kexpand <- function(wd, ht, cap, res, echo) {
cat(knit(text = knit_expand(text =
sprintf("```{r %s, results='%s', echo = '%s',fig.keep='all', fig.width=%s, fig.height=%s}\n.pl\n```", cap, res, echo, wd, ht)
)))}
special_kexpand <- function(wd, ht, cap, res, echo) {
cat(knit(text = knit_expand(text =
sprintf("```{r %s, results='%s', echo = '%s',fig.keep='all', fig.width=%s, fig.height=%s}\ninteractive_treemap(reducedTerms[[1]][[i]])\n```", cap, res, echo, wd, ht)
)))}
# Loop through each FC value
headers <- Comp
types <- c("Dot plot", "Table", "Upset plot", "Dendrogram", "Scatter", "Parent term", "Treemap")
for (i in 2:length(headers)) {
cat(paste0("### ",headers[i],"{.tabset .tabset-pills} \n\n"))
cat(paste0("#### ",types[[1]]," \n"))
.pl <- dot[[i]]
kexpand(wd = 8,ht = 10,cap = paste0("dot",i),res = "markup",echo = "TRUE")
cat("\n\n")
cat(paste0("#### ",types[[2]]," \n"))
.pl <- tab[[i]]
kexpand(wd = 11,ht = 8,cap = paste0("tab",i), res = "markup",echo = "TRUE")
cat("\n\n")
cat(paste0("#### ",types[[3]]," \n"))
.pl <- upset[[i]]
kexpand(wd = 11,ht = 9,cap = paste0("upset",i),res = "markup",echo = "TRUE")
cat("\n\n")
cat(paste0("#### ",types[[4]]," \n"))
.pl <- den[[i]]
kexpand(wd = 8,ht = 11,cap = paste0("den",i),res = "markup",echo = "TRUE")
cat("\n\n")
cat(paste0("#### ",types[[5]]," \n"))
.pl <- scatter[[i]]
kexpand(wd = 8,ht = 8,cap = paste0("scatter",i),res = "markup",echo = "TRUE")
cat("\n\n")
cat(paste0("Interactive Scatter \n"))
.pl <- scatter_plotly[[i]]
kexpand(wd = 9,ht = 9,cap = paste0("scatter_interactive",i),res = "markup",echo = "TRUE")
cat("\n\n")
cat(paste0("3D scatter \n"))
.pl <- scatter_3d[[i]]
kexpand(wd = 9,ht = 9,cap = paste0("scatter_3d",i),res = "markup",echo = "TRUE")
cat("\n\n")
cat(paste0("#### ",types[[6]]," \n"))
.pl <- semSim_dot[[i]]
kexpand(wd = 9,ht = 12 ,cap = paste0("parentTerm",i),res = "markup",echo = "TRUE")
cat("\n\n")
cat(paste0("#### ",types[[7]]," \n"))
# special_kexpand(wd = 9,ht = 9,cap = paste0("treemap",i),res = "hide",echo = "FALSE")
# cat("\n\n")
# cat(paste0("Interactive Treemap\n"))
# .pl <- interactive_treemap(reducedTerms[[i]])
special_kexpand(wd = 9,ht = 9,cap = paste0("treemap",i),res = "markup",echo = "FALSE")
cat("\n\n")
}DT+Treg vs veh
Dot plot
.pl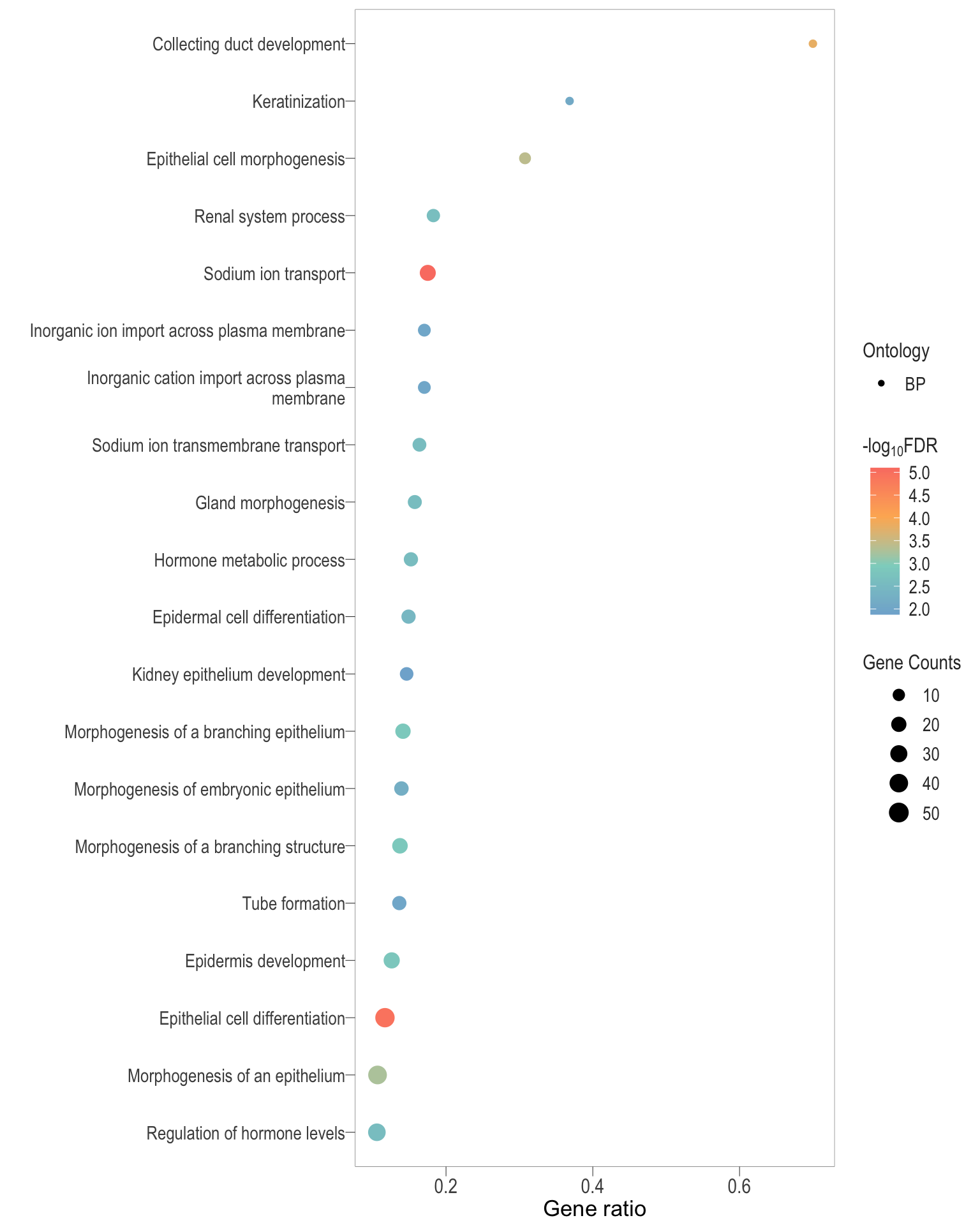
Table
.plUpset plot
.pl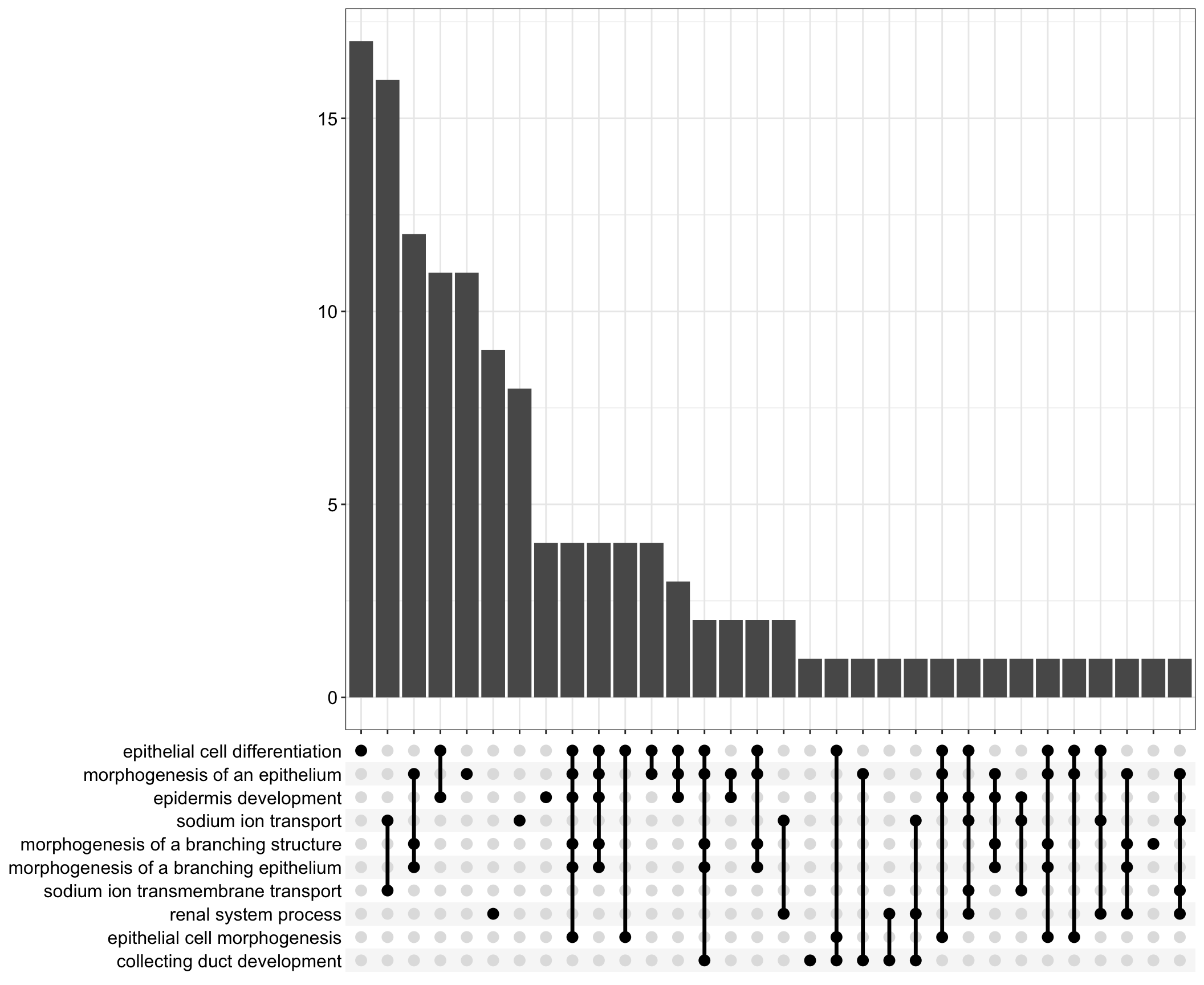
Dendrogram
.pl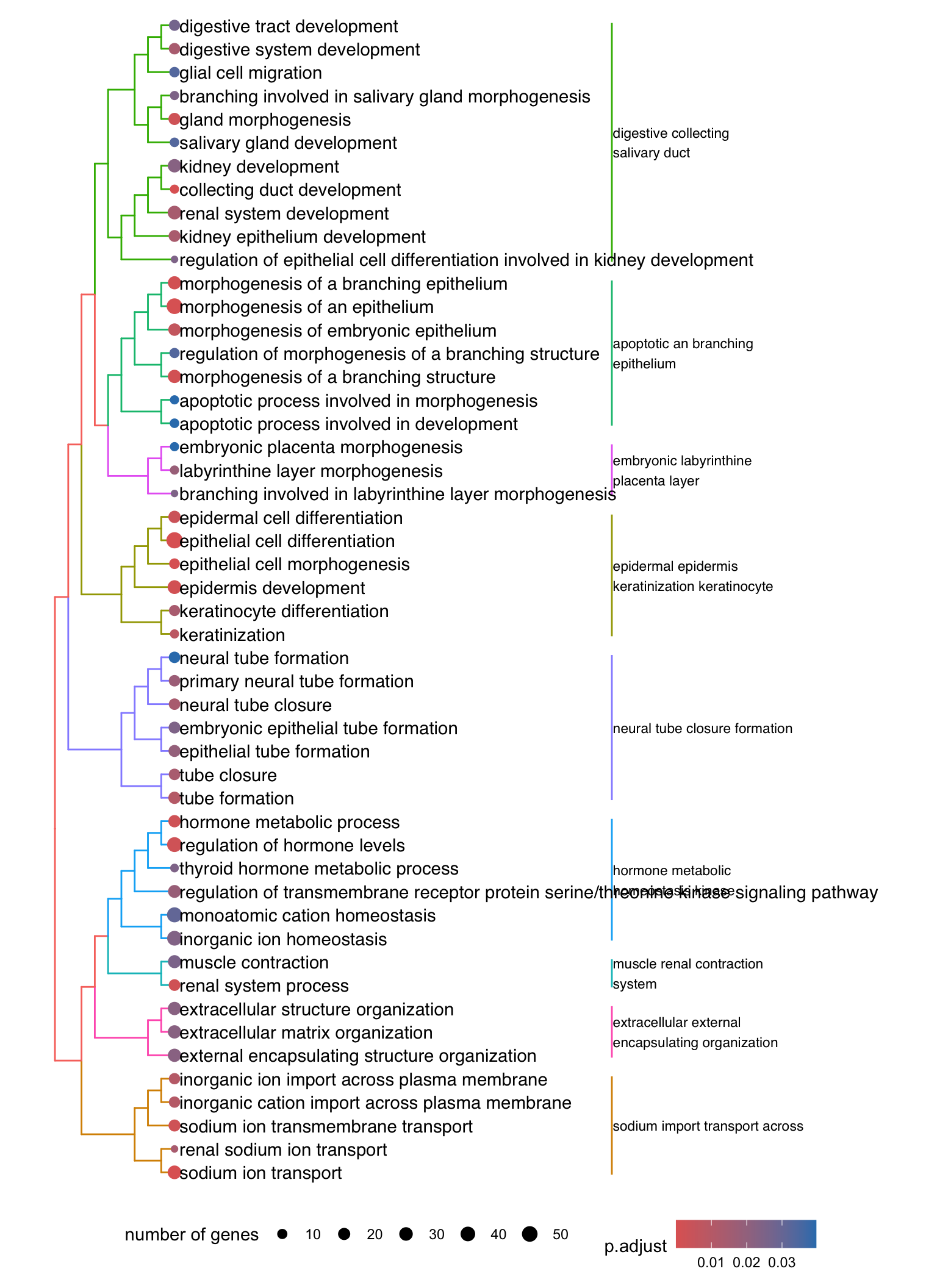
Scatter
.pl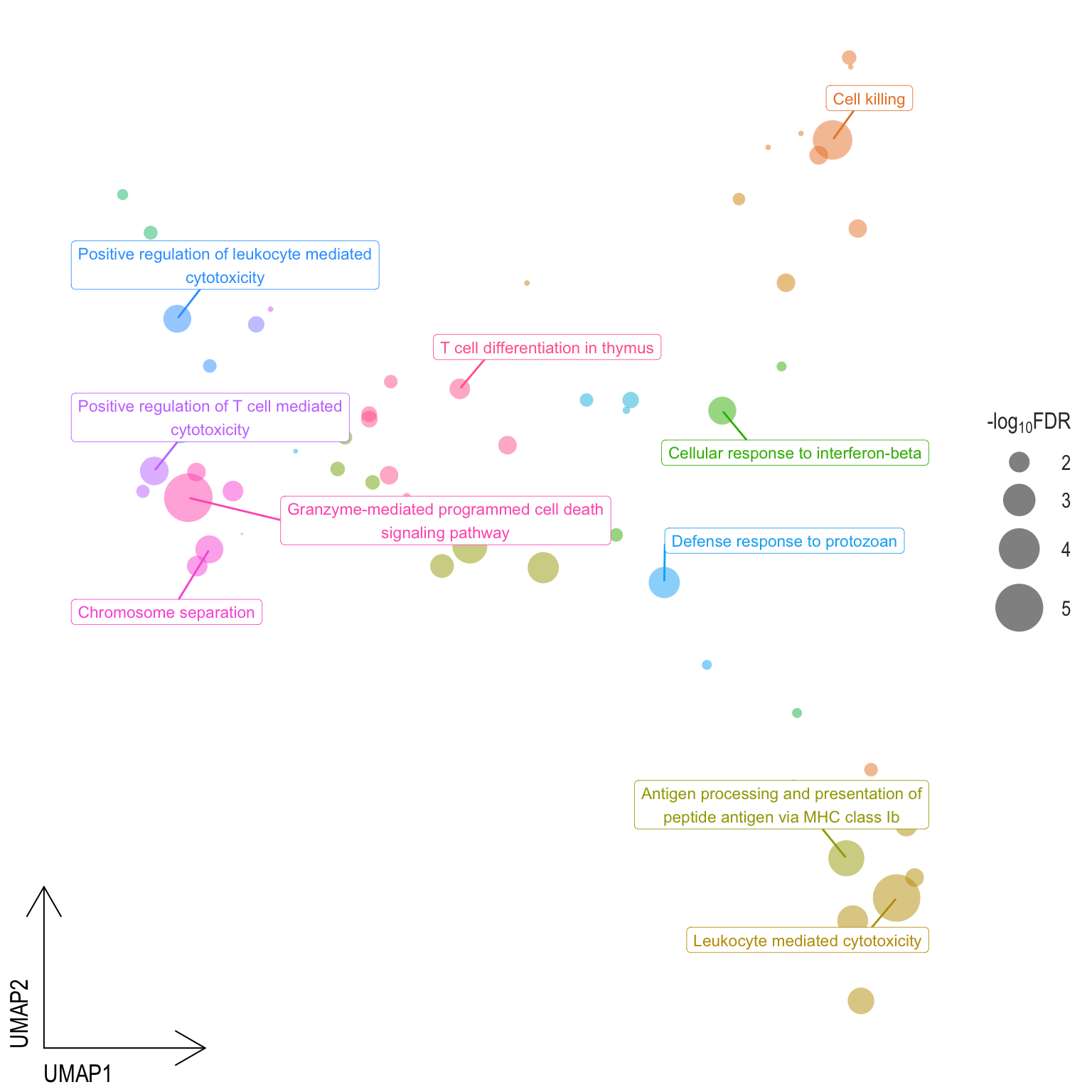
Interactive Scatter
.pl3D scatter
.plParent term
.pl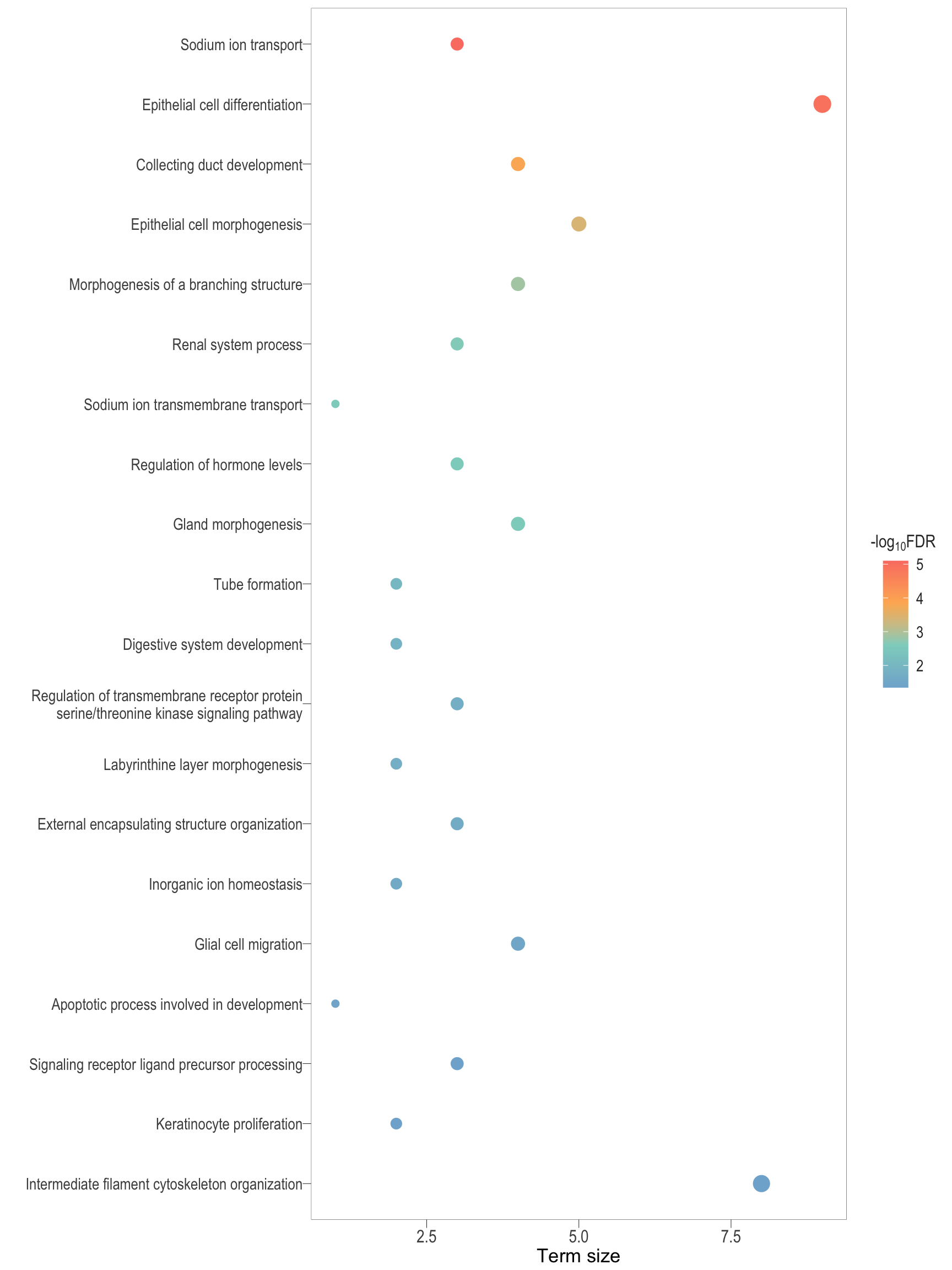

DT+Treg vs DT
Dot plot
.pl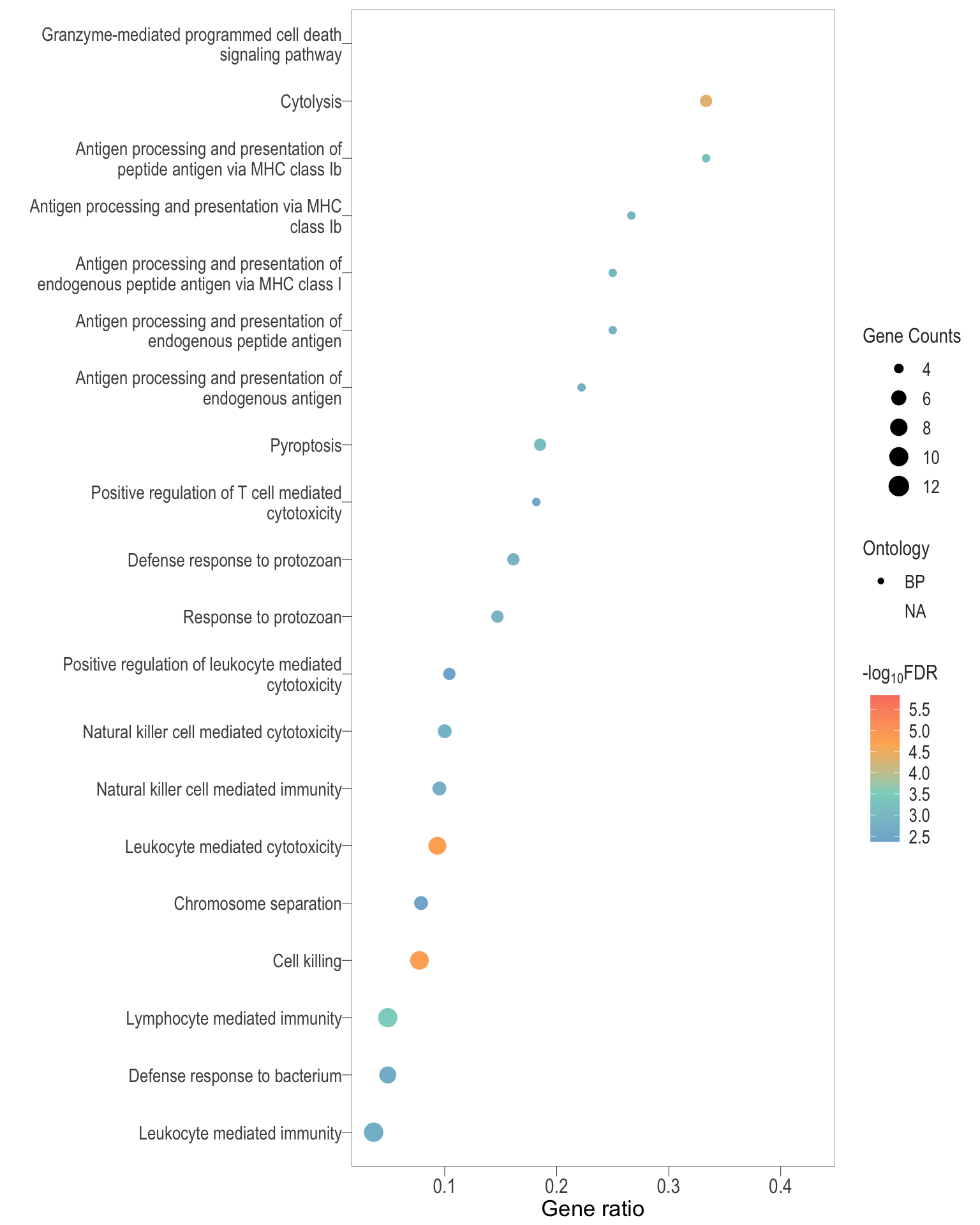
Table
.plUpset plot
.pl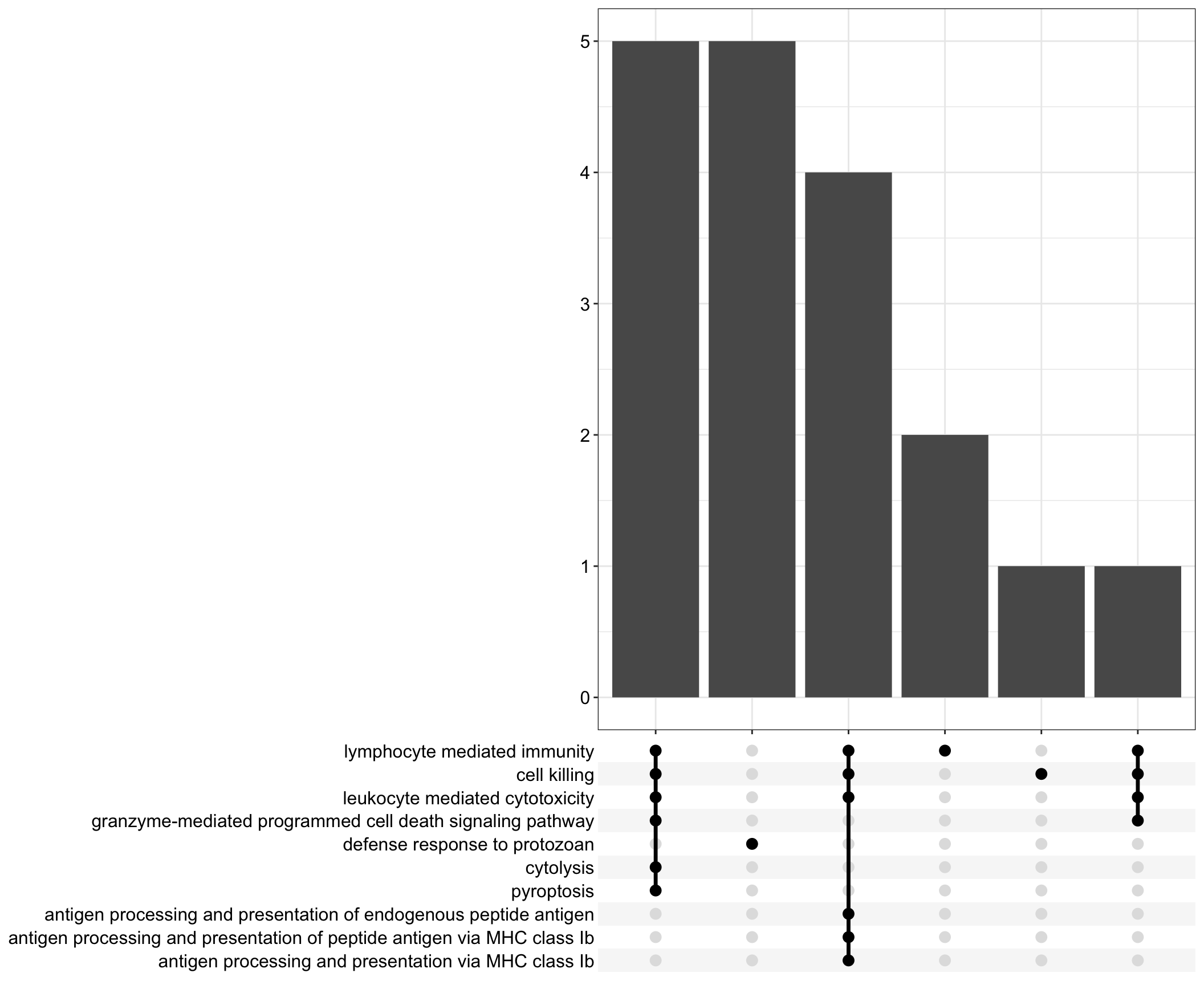
Dendrogram
.pl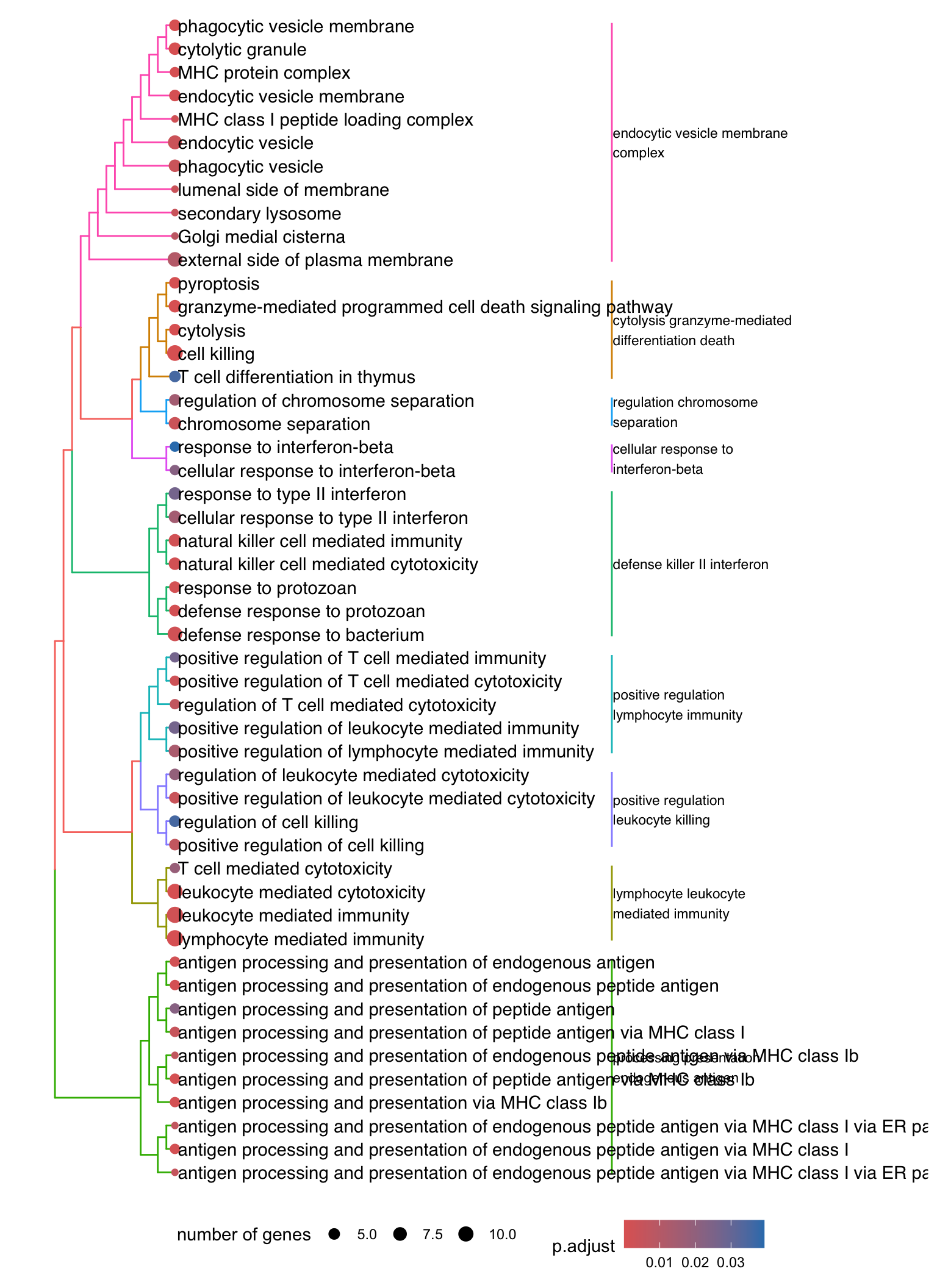
Scatter
.pl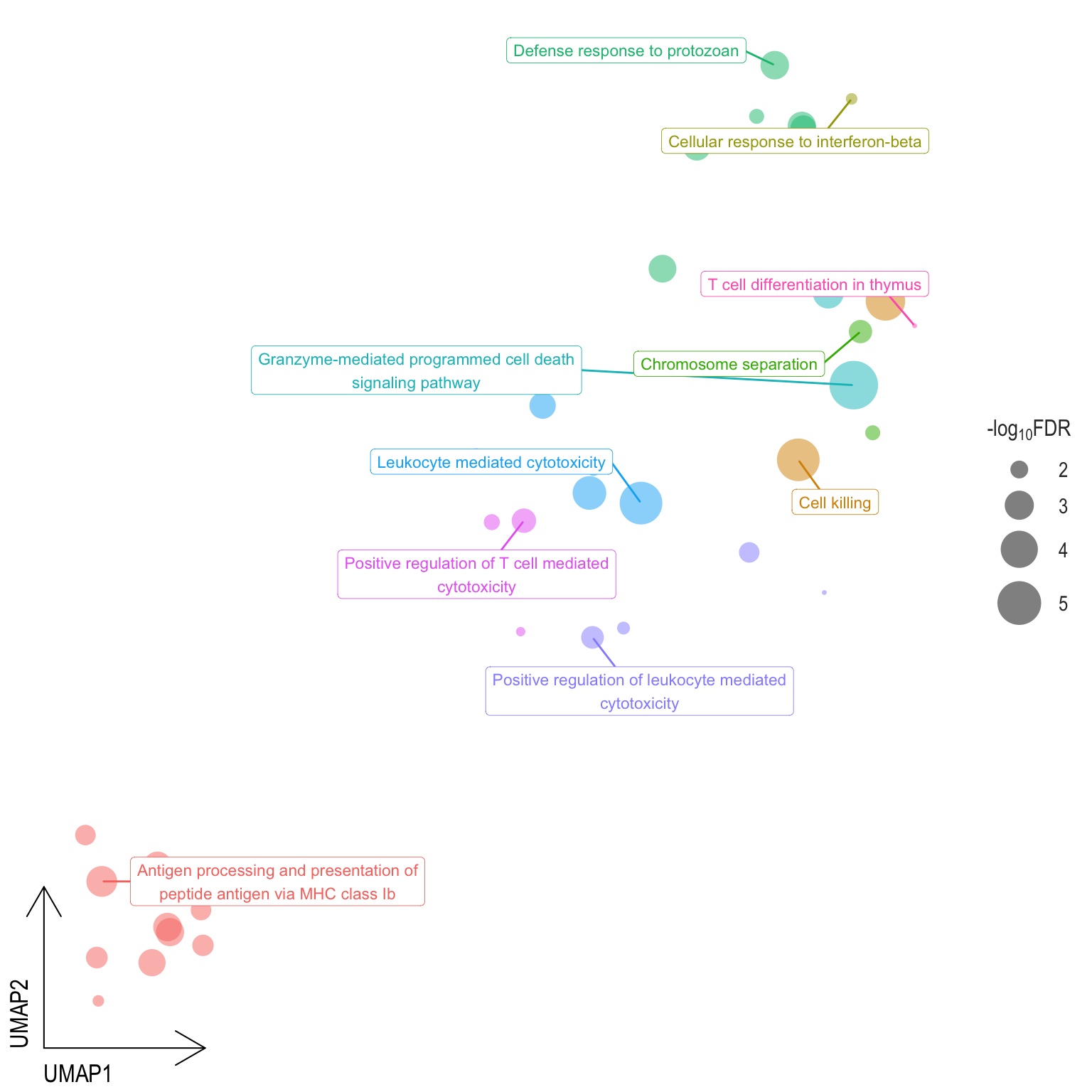
Interactive Scatter
.pl3D scatter
.plParent term
.pl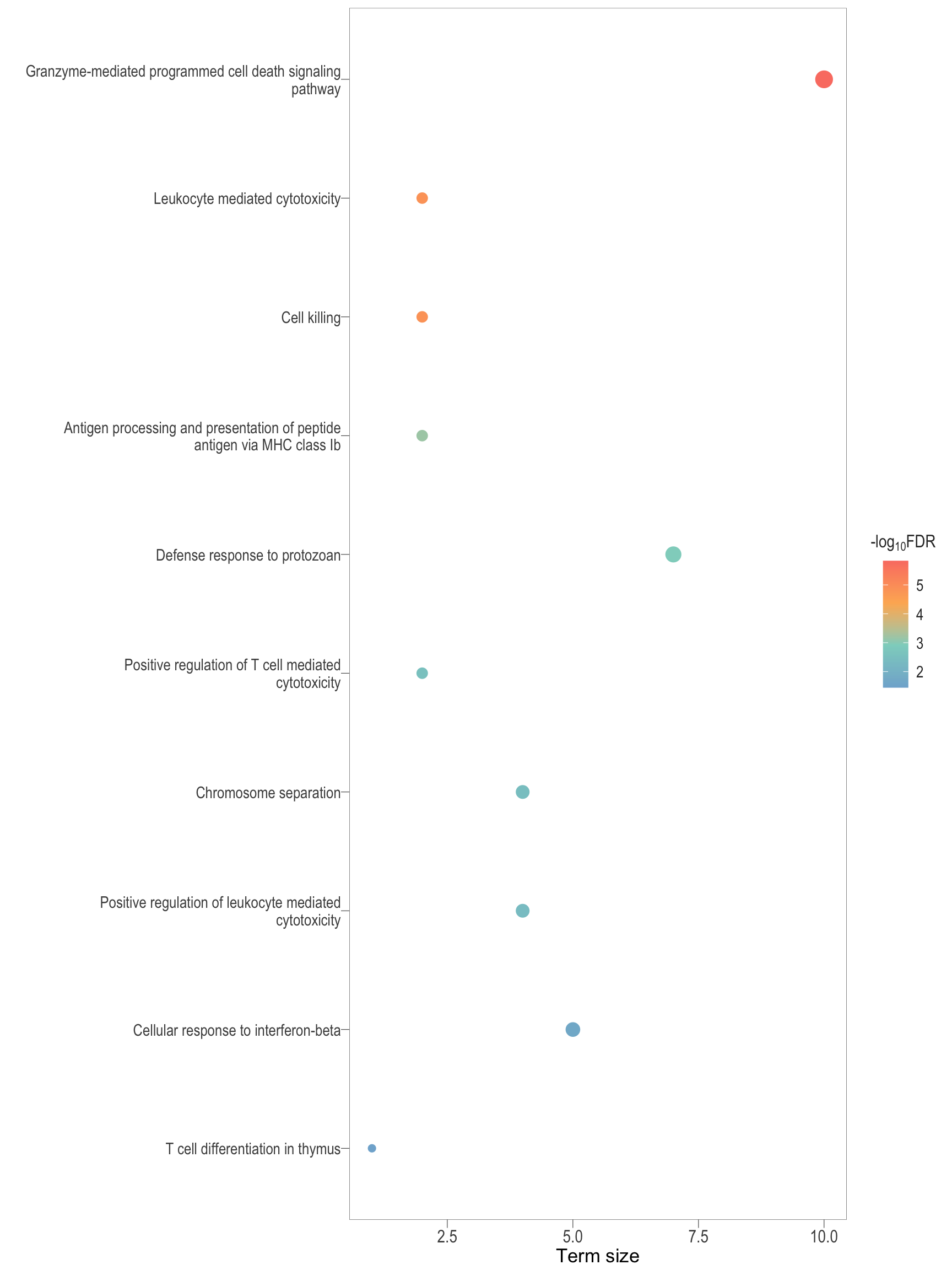
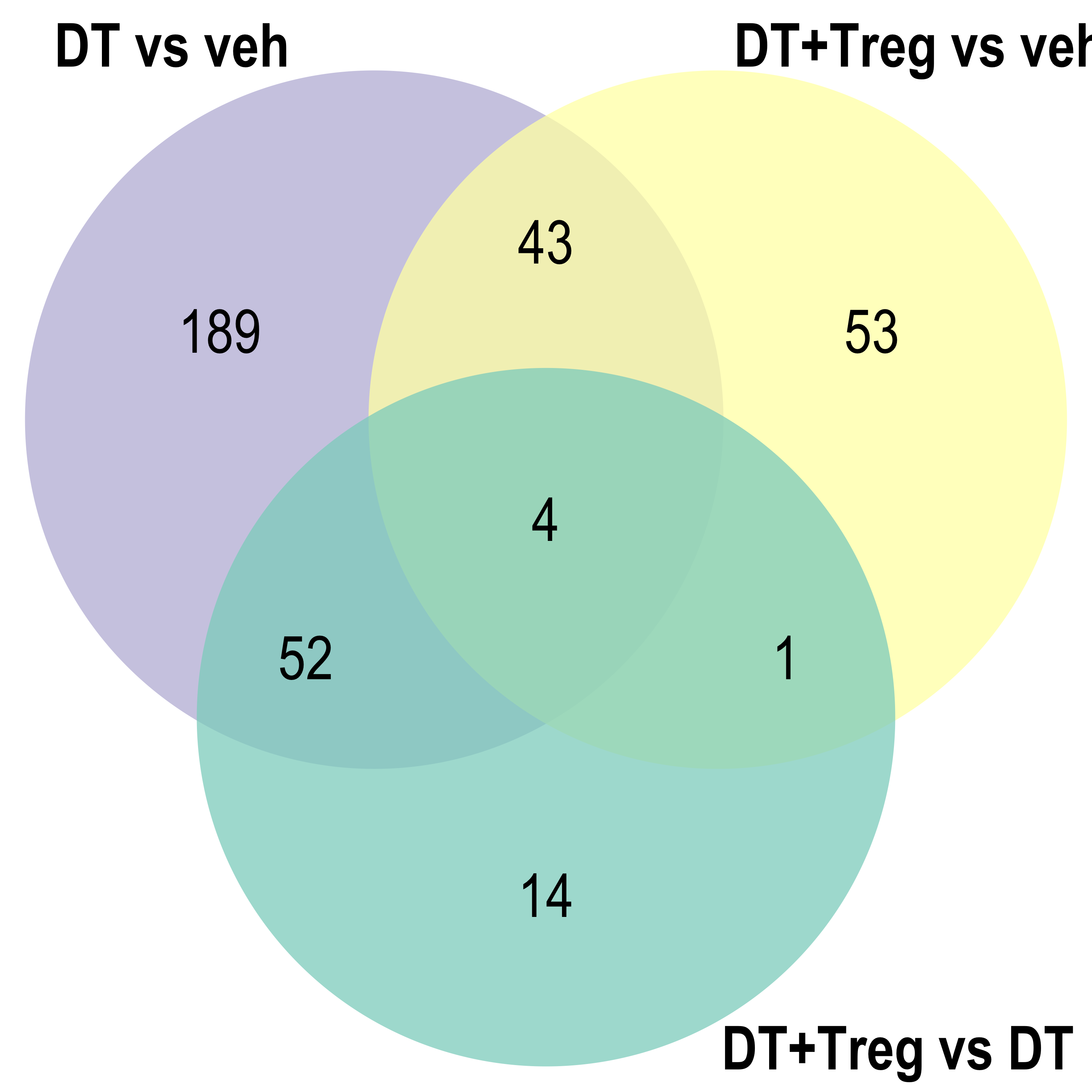
Combined
Venn diagram
Dot plot
# combine all df in list into one df
go_dot_all <- as.data.frame(do.call(rbind, enrichGO_sig)) %>%
rownames_to_column("group")
# clean group names and change to factor
go_dot_all$group <- gsub(pattern = "\\..*", "", go_dot_all$group) %>% as.factor()
# factor the descriptions
top10 <- as.data.frame(do.call(rbind, lapply(enrichGO_sig, "[", 1:15,3))) %>% rownames_to_column("group")
top10 <- melt(top10, "group")
terms <- top10$value %>% as.factor() %>% levels()
go_dot_all <- go_dot_all[go_dot_all$Description %in% terms,]
go_dot_all$group <- factor(go_dot_all$group,levels = c("DT vs veh", "DT+Treg vs veh", "DT+Treg vs DT" ))
go_dot_all$Description <- go_dot_all$Description %>% str_wrap(55)
combine_go <- ggplot(go_dot_all) +
geom_point(aes(x = group, y = reorder(Description, logFDR), colour = logFDR, size = Count, shape = ONTOLOGY %>% as.factor())) +
scale_color_gradientn(colors = rev(c("#FB8072","#FDB462","#8DD3C7","#80B1D3")),
values = scales::rescale(c(min(go_dot_all$logFDR), max(go_dot_all$logFDR))),
breaks = scales::pretty_breaks(n = 5)) +
scale_size(range = c(2,5)) +
labs(x = "", y = "", color = expression("-log"[10] * "FDR"), size = "Counts", shape = "Ontology")+
bossTheme(base_size = 14,legend = "right")
if(savePlots == TRUE) {
ggsave(filename = paste0("combine_go_dot.svg"), plot = combine_go, path = here::here("2_plots/3_FA/go/"),
width = 20, height = 25, units = "cm")
}
saveRDS(combine_go, here::here("0_data/rds_plots/go_combined_dotPlot.rds"))
combine_go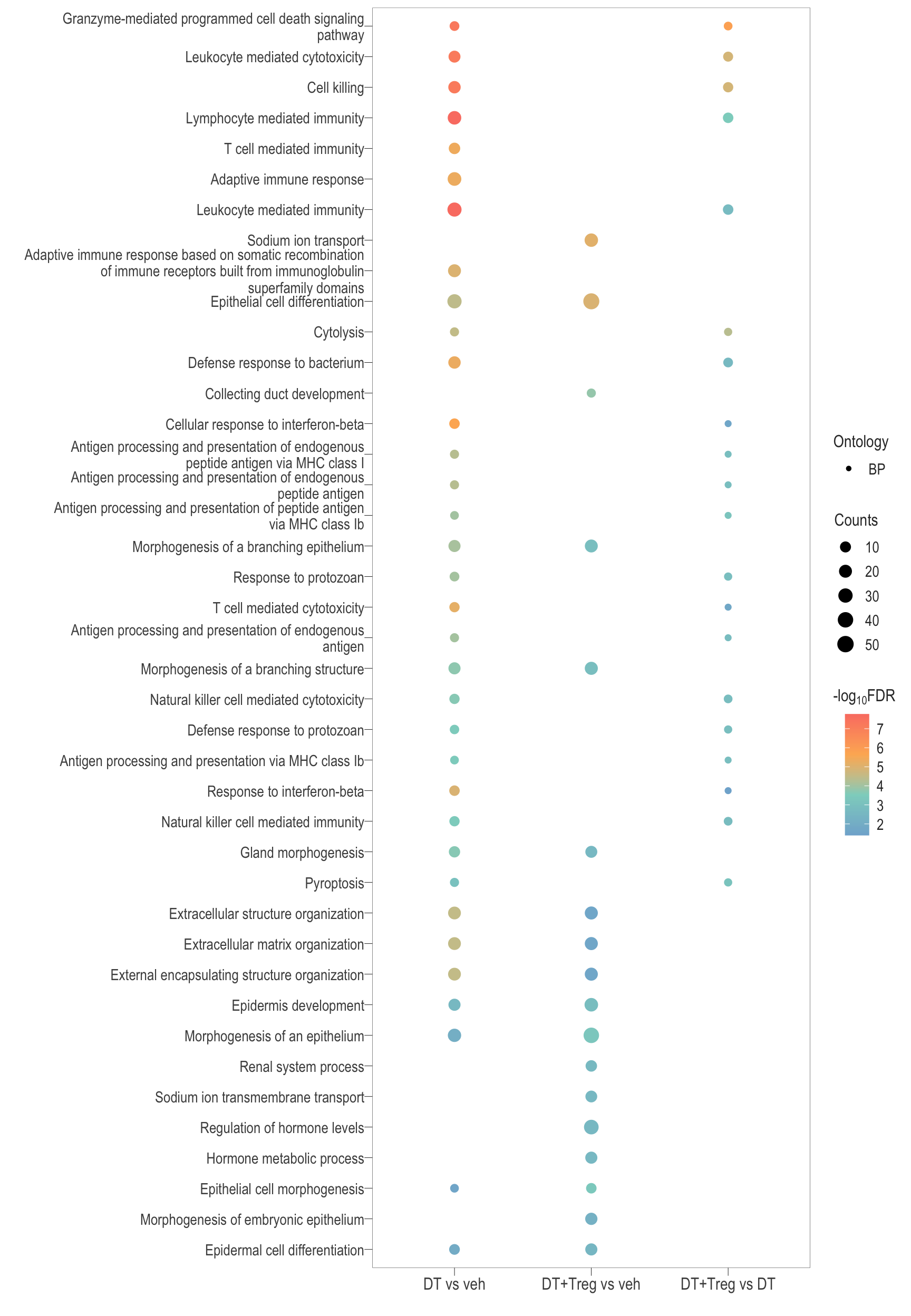
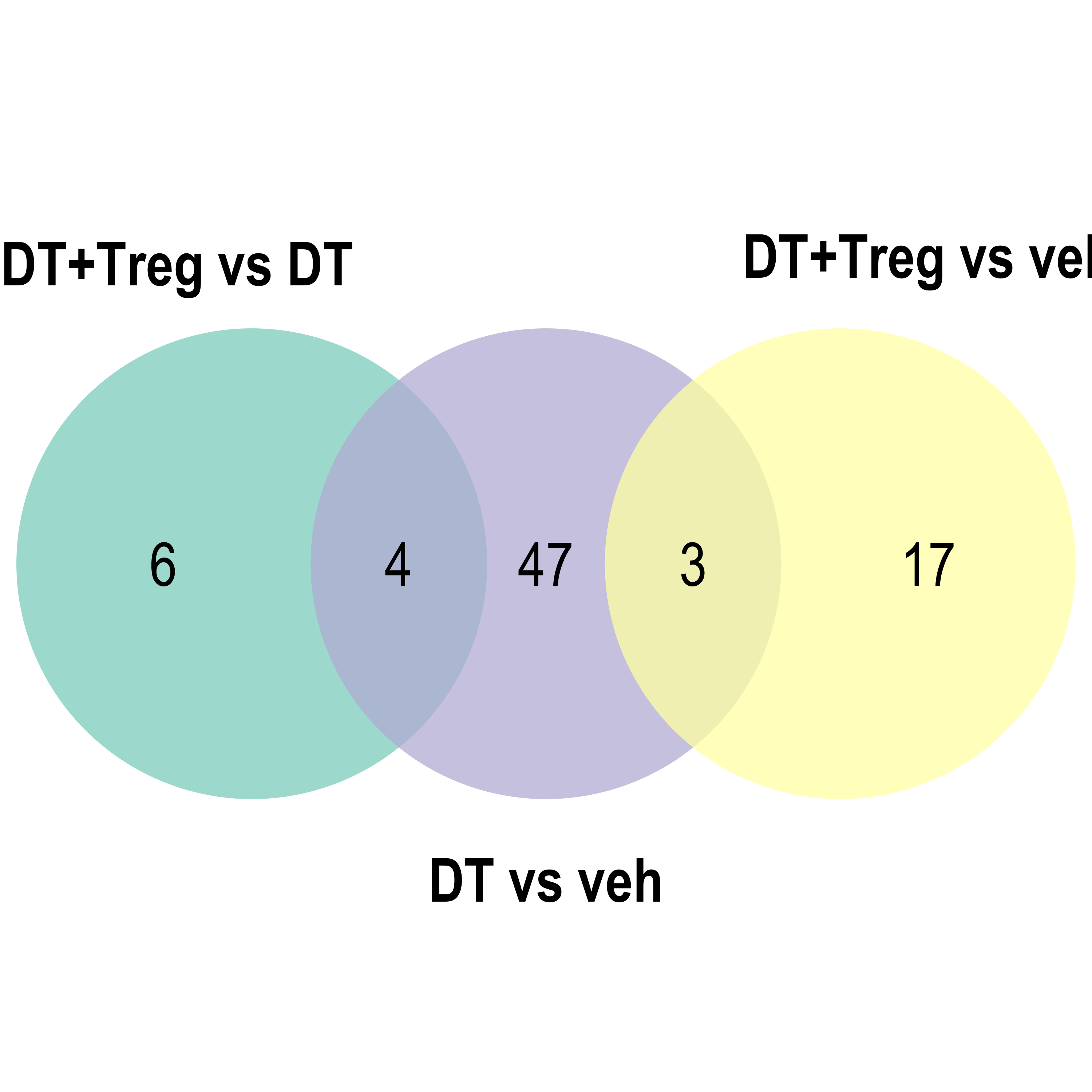
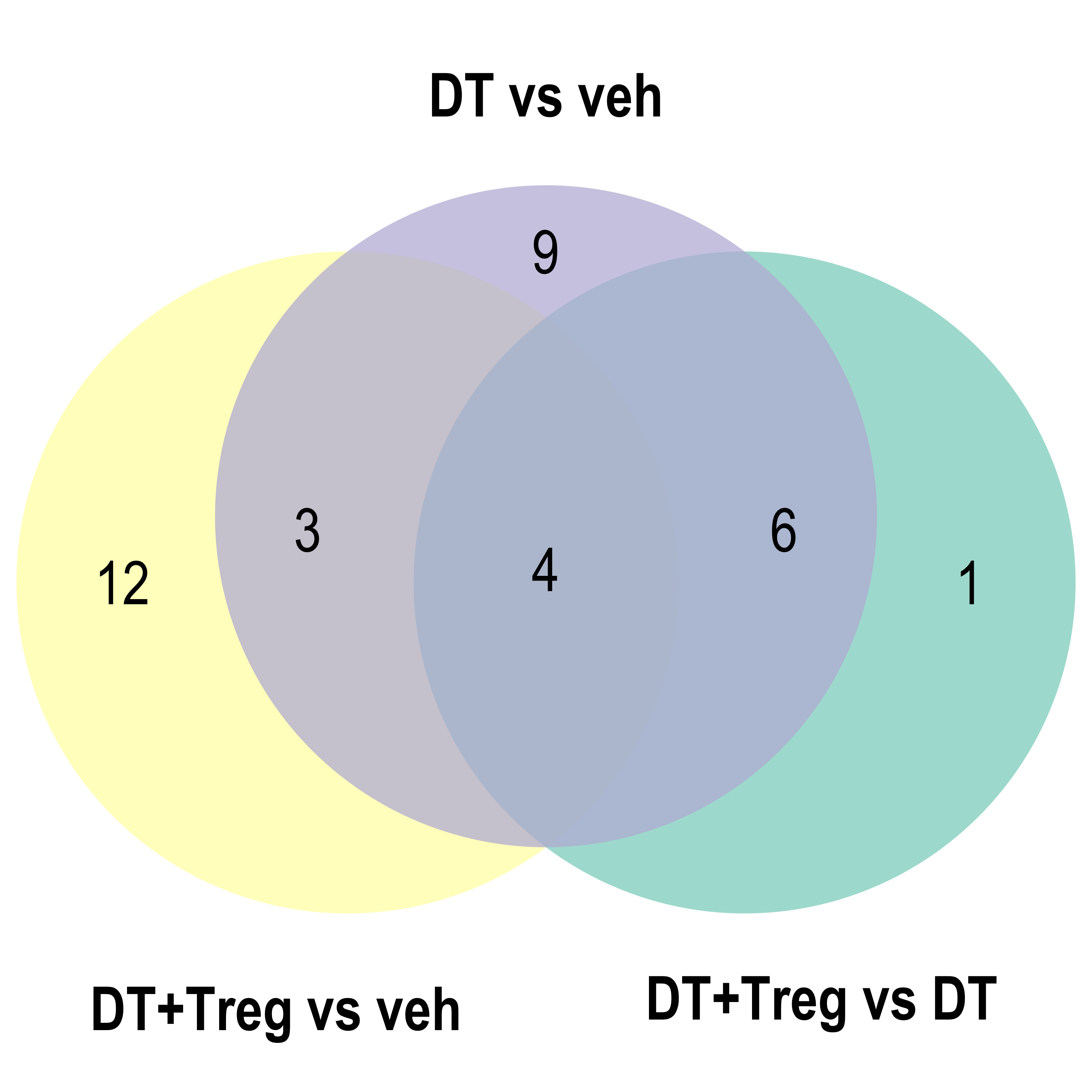
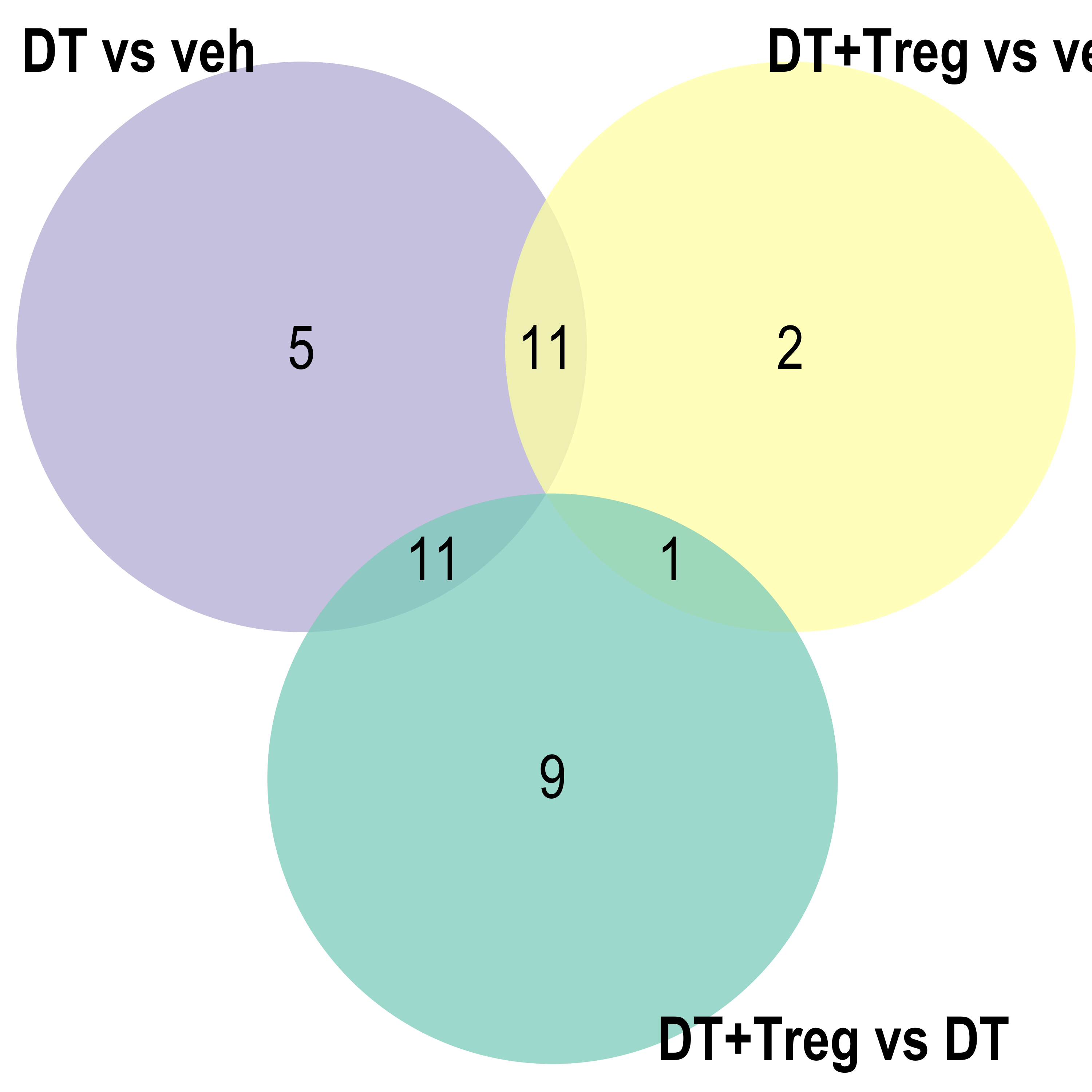
Parent term Venn
# cat.pos = c(-27, 27, 135),
# cat.dist = c(0.055, 0.055, 0.085)
futile.logger::flog.threshold(futile.logger::ERROR, name = "VennDiagramLogger")NULLcat.pos <- list(BP =c(-15,180,15),
MF =c(-170,170,0),
CC =c(-27, 27, 135))
cat.dist <- list(BP =c(0.05, .09, .045),
MF =c(0.085, 0.06, 0.085),
CC =c(0.055, 0.055, 0.085))
for(ont in Ont){
venn.diagram(x = list("DT vs veh" = reducedTerms[[ont]][[1]]$parentTerm %>% as.character(),
"DT+Treg vs veh" = reducedTerms[[ont]][[2]]$parentTerm %>% as.character(),
"DT+Treg vs DT" = reducedTerms[[ont]][[3]]$parentTerm %>% as.character()),
filename = here::here(paste0("docs/assets/go_parTerm_",ont,"_venn.png")),
lwd = 2,
disable.logging = T,
fill = compColour,
alpha = 0.75,
lty = 'blank',
imagetype = "png",
# main = paste0(ont, "parent terms"),
# Numbers
cex = 2,
fontface = "plain",
fontfamily = "Arial Narrow",
# Set names
cat.cex = 2,
cat.fontface = "bold",
cat.fontfamily = "Arial Narrow",
cat.default.pos = "outer",
cat.pos = cat.pos[[ont]],
cat.dist = cat.dist[[ont]]
)
}
Parent term dot
reducedTerms_all <- readRDS(here::here("0_data/rds_objects/reducedTerms_all.rds"))
reducedTerms_all_BP <- reducedTerms_all[!reducedTerms_all$ont %in% c("MF", "CC"),]
reducedTerms_all_BP <- reducedTerms_all_BP[!reducedTerms_all_BP$comparison %in% c("DT+Treg vs veh"),]%>% dplyr::arrange(desc(score))
reducedTerms_all_BP$parentTerm <- reducedTerms_all_BP$parentTerm %>% str_wrap(38)
dotplot <- function(data){
ggplot(data) +
geom_point(aes(x = comparison, y = reorder(parentTerm, score), colour = score, size = parentTerm_size), alpha=0.8) +
scale_color_gradientn(colours = rev(c("#FB8072","#FDB462","#8DD3C7","#80B1D3")),
limits = c(min(reducedTerms_all_BP$score), max(reducedTerms_all_BP$score)),
breaks = scales::pretty_breaks(n = 5)) +
scale_size(range = c(2,5),limits = c(min(reducedTerms_all_BP$parentTerm_size), max(reducedTerms_all_BP$parentTerm_size))) +
labs(x = "", y = "", color = expression("-log"[10] * "FDR"), size = "Term size")+
bossTheme(base_size = 14,legend = "bottom")
}
t <- wrap_plots(list(dotplot(reducedTerms_all_BP[1:32, ]), dotplot(reducedTerms_all_BP[32:nrow(reducedTerms_all_BP), ]))) +
plot_layout(guides = "collect") &
bossTheme(base_size = 12, legend = "none") &
theme(legend.box.margin = margin(-5, 0, 0, -50, unit = "mm"),
# plot.margin = margin(1, 1, 1, 0, unit = "pt"),
axis.text.y = element_text(family = "Arial Narrow", face = "plain", size = 10, hjust = 1),
axis.text.x = element_text(family = "Arial", face = "plain", size = 11, hjust = 1, vjust = 1, angle = 40))
t
Biological processes parent terms
saveRDS(t, here::here("0_data/rds_plots/go_combined_parTerm_dotPlot.rds"))
ggsave(filename = "parentTerm_all.png", plot = t, path = here::here("2_plots/3_FA/go/"),
width = 21, height = 27, units = "cm")Export Data
The following are exported:
- GO.xlsx - This spreadsheet contains all significantly enriched GO terms. NOTE:
# save to excel
writexl::write_xlsx(x = enrichGO_sig, here::here("3_output/GO_sig.xlsx"))
sessionInfo()R version 4.4.1 (2024-06-14)
Platform: aarch64-apple-darwin20
Running under: macOS Sonoma 14.5
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Australia/Adelaide
tzcode source: internal
attached base packages:
[1] stats4 grid stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] htmltools_0.5.8.1 knitr_1.48 pandoc_0.2.0
[4] patchwork_1.2.0 enrichplot_1.24.2 org.Mm.eg.db_3.19.1
[7] AnnotationDbi_1.66.0 IRanges_2.38.1 S4Vectors_0.42.1
[10] Biobase_2.64.0 BiocGenerics_0.50.0 clusterProfiler_4.12.2
[13] Glimma_2.14.0 edgeR_4.2.1 limma_3.60.4
[16] data.table_1.15.4 GOSemSim_2.30.0 plotly_4.10.4
[19] d3treeR_0.1 rrvgo_1.16.0 ggrepel_0.9.5.9999
[22] ggbiplot_0.6.2 gridExtra_2.3 VennDiagram_1.7.3
[25] futile.logger_1.4.3 extrafont_0.19 DT_0.33
[28] kableExtra_1.4.0 lubridate_1.9.3 forcats_1.0.0
[31] stringr_1.5.1 purrr_1.0.2 tidyr_1.3.1
[34] ggplot2_3.5.1 tidyverse_2.0.0 reshape2_1.4.4
[37] tibble_3.2.1 readr_2.1.5 magrittr_2.0.3
[40] dplyr_1.1.4
loaded via a namespace (and not attached):
[1] splines_4.4.1 later_1.3.2
[3] ggplotify_0.1.2 polyclip_1.10-7
[5] XML_3.99-0.17 lifecycle_1.0.4
[7] rprojroot_2.0.4 NLP_0.2-1
[9] lattice_0.22-6 MASS_7.3-61
[11] crosstalk_1.2.1 sass_0.4.9
[13] rmarkdown_2.27 jquerylib_0.1.4
[15] yaml_2.3.10 httpuv_1.6.15
[17] askpass_1.2.0 reticulate_1.38.0
[19] cowplot_1.1.3 DBI_1.2.3
[21] RColorBrewer_1.1-3 abind_1.4-5
[23] zlibbioc_1.50.0 GenomicRanges_1.56.1
[25] ggraph_2.2.1 yulab.utils_0.1.5
[27] rappdirs_0.3.3 tweenr_2.0.3
[29] git2r_0.33.0 GenomeInfoDbData_1.2.12
[31] data.tree_1.1.0 tm_0.7-13
[33] tidytree_0.4.6 pheatmap_1.0.12
[35] umap_0.2.10.0 RSpectra_0.16-2
[37] svglite_2.1.3 gridSVG_1.7-5
[39] codetools_0.2-20 DelayedArray_0.30.1
[41] DOSE_3.30.2 xml2_1.3.6
[43] ggforce_0.4.2 tidyselect_1.2.1
[45] aplot_0.2.3 farver_2.1.2
[47] UCSC.utils_1.0.0 viridis_0.6.5
[49] matrixStats_1.3.0 jsonlite_1.8.8
[51] tidygraph_1.3.1 systemfonts_1.1.0
[53] ggnewscale_0.5.0 tools_4.4.1
[55] ragg_1.3.2 treeio_1.28.0
[57] Rcpp_1.0.13 glue_1.7.0
[59] Rttf2pt1_1.3.12 SparseArray_1.4.8
[61] here_1.0.1 xfun_0.46
[63] DESeq2_1.44.0 qvalue_2.36.0
[65] MatrixGenerics_1.16.0 GenomeInfoDb_1.40.1
[67] withr_3.0.1 formatR_1.14
[69] fastmap_1.2.0 ggh4x_0.2.8
[71] fansi_1.0.6 openssl_2.2.0
[73] digest_0.6.36 gridGraphics_0.5-1
[75] timechange_0.3.0 R6_2.5.1
[77] mime_0.12 textshaping_0.4.0
[79] colorspace_2.1-1 GO.db_3.19.1
[81] RSQLite_2.3.7 utf8_1.2.4
[83] generics_0.1.3 graphlayouts_1.1.1
[85] httr_1.4.7 htmlwidgets_1.6.4
[87] S4Arrays_1.4.1 scatterpie_0.2.3
[89] whisker_0.4.1 pkgconfig_2.0.3
[91] gtable_0.3.5 blob_1.2.4
[93] workflowr_1.7.1 XVector_0.44.0
[95] shadowtext_0.1.4 fgsea_1.30.0
[97] ggupset_0.4.0 scales_1.3.0
[99] png_0.1-8 wordcloud_2.6
[101] ggfun_0.1.5 lambda.r_1.2.4
[103] rstudioapi_0.16.0 tzdb_0.4.0
[105] nlme_3.1-165 cachem_1.1.0
[107] parallel_4.4.1 HDO.db_0.99.1
[109] treemap_2.4-4 pillar_1.9.0
[111] vctrs_0.6.5 slam_0.1-52
[113] promises_1.3.0 xtable_1.8-4
[115] extrafontdb_1.0 evaluate_0.24.0
[117] cli_3.6.3 locfit_1.5-9.10
[119] compiler_4.4.1 futile.options_1.0.1
[121] rlang_1.1.4 crayon_1.5.3
[123] labeling_0.4.3 plyr_1.8.9
[125] fs_1.6.4 writexl_1.5.0
[127] stringi_1.8.4 viridisLite_0.4.2
[129] gridBase_0.4-7 BiocParallel_1.38.0
[131] munsell_0.5.1 Biostrings_2.72.1
[133] lazyeval_0.2.2 Matrix_1.7-0
[135] hms_1.1.3 bit64_4.0.5
[137] KEGGREST_1.44.1 statmod_1.5.0
[139] shiny_1.9.1 highr_0.11
[141] SummarizedExperiment_1.34.0 igraph_2.0.3
[143] memoise_2.0.1 bslib_0.8.0
[145] ggtree_3.12.0 fastmatch_1.1-4
[147] bit_4.0.5 gson_0.1.0
[149] ape_5.8