DGE Analysis
Ha Tran
08-01-2024
Last updated: 2024-08-02
Checks: 7 0
Knit directory: 5_Treg_uNK/1_analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(12345) was run prior to running the
code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 73ae14f. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Untracked files:
Untracked: .DS_Store
Untracked: .gitignore
Untracked: cellChat.Rmd
Unstaged changes:
Modified: 0_data/rds_plots/deHmap_plots.rds
Modified: 0_data/rds_plots/go_combined_parTerm_dotPlot.rds
Modified: 0_data/rds_plots/go_parTerm_dotPlot.rds
Modified: 0_data/rds_plots/kegg_path_Hmap.rds
Deleted: 1_analysis/cellChat.Rmd
Modified: 3_output/GO_sig.xlsx
Modified: 3_output/KEGG_all.xlsx
Modified: 3_output/KEGG_sig.xlsx
Modified: 3_output/de_genes_all.xlsx
Modified: 3_output/de_genes_sig.xlsx
Modified: 3_output/reactome_all.xlsx
Modified: 3_output/reactome_sig.xlsx
Modified: sampleHeatmap.rds
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (1_analysis/deAnalysis.Rmd) and HTML
(docs/deAnalysis.html) files. If you’ve configured a remote
Git repository (see ?wflow_git_remote), click on the
hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 73ae14f | Ha Tran | 2024-08-02 | Large update with final visualisations |
| html | 73ae14f | Ha Tran | 2024-08-02 | Large update with final visualisations |
| html | e9e7671 | tranmanhha135 | 2024-02-08 | Build site. |
| Rmd | 8da2e31 | tranmanhha135 | 2024-02-08 | workflowr::wflow_publish(here::here("1_analysis/*.Rmd")) |
| Rmd | d8d23ee | tranmanhha135 | 2024-01-13 | im on holiday |
| html | d8d23ee | tranmanhha135 | 2024-01-13 | im on holiday |
| html | 36aeb85 | Ha Manh Tran | 2024-01-13 | Build site. |
| Rmd | a957cff | Ha Manh Tran | 2024-01-13 | workflowr::wflow_publish(here::here("1_analysis/*Rmd")) |
| Rmd | 221e2fa | tranmanhha135 | 2024-01-10 | fixed error |
| html | 221e2fa | tranmanhha135 | 2024-01-10 | fixed error |
| html | 762020e | tranmanhha135 | 2024-01-09 | Build site. |
| Rmd | c6d389f | tranmanhha135 | 2024-01-09 | workflowr::wflow_publish(here::here("1_analysis/*.Rmd")) |
| Rmd | f2e3750 | tranmanhha135 | 2024-01-08 | completed DE |
| Rmd | 05fa0b3 | tranmanhha135 | 2024-01-06 | added description |
Data Setup
# working with data
library(readxl)
library(dplyr)
library(magrittr)
library(readr)
library(tibble)
library(reshape2)
library(tidyverse)
library(ComplexHeatmap)
library(scales)
library(plyr)
# Visualisation:
library(kableExtra)
library(ggplot2)
library(grid)
library(pander)
library(cowplot)
library(pheatmap)
library(VennDiagram)
library(DT)
library(patchwork)
library(kableExtra)
library(extrafont)
loadfonts(device = "all")
# Custom ggplot
library(ggplotify)
library(ggpubr)
library(ggrepel)
library(viridis)
# Bioconductor packages:
library(edgeR)
library(limma)
library(Glimma)
library(pandoc)
library(knitr)
opts_knit$set(progress = FALSE, verbose = FALSE)
opts_chunk$set(warning=FALSE, message=FALSE, echo=FALSE)Import DGElist Data
DGElist object containing the raw feature count, sample metadata, and gene metadata, created in the Set Up stage.
Initial Parameterisation
The varying methods used to identify differential expression all rely on similar initial parameters. These include:
The Design Matrix,
Estimation of Dispersion, and
Contrast Matrix
Design Matrix
The experimental design can be parameterised in a one-way layout where one coefficient is assigned to each group. The design matrix formulated below contains the predictors of each sample
Contrast Matrix
The contrast matrix is required to provide a coefficient to each comparison and later used to test for significant differential expression with each comparison group
Limma-Voom
Apply voom transformation
Voom is used to estimate the mean-variance relationship of the data, which is then used to calculate and assign a precision weight for each of the observation (gene). This observational level weights are then used in a linear modelling process to adjust for heteroscedasticity. Log count (logCPM) data typically show a decreasing mean-variance trend with increasing count size (expression).
However, for some dataset with potential sample outliers,
voomWithQualityWeights can be used to calculate
sample-specific quality weights. The application of observational and
sample-specific weights can objectively and systematically correct for
outliers and better than manually removing samples in cases where there
are no clear-cut reasons for replicate variations. Thus, linear model
will be applied to the voom transformation with observational and
sample-specific weights.
Observational level weights
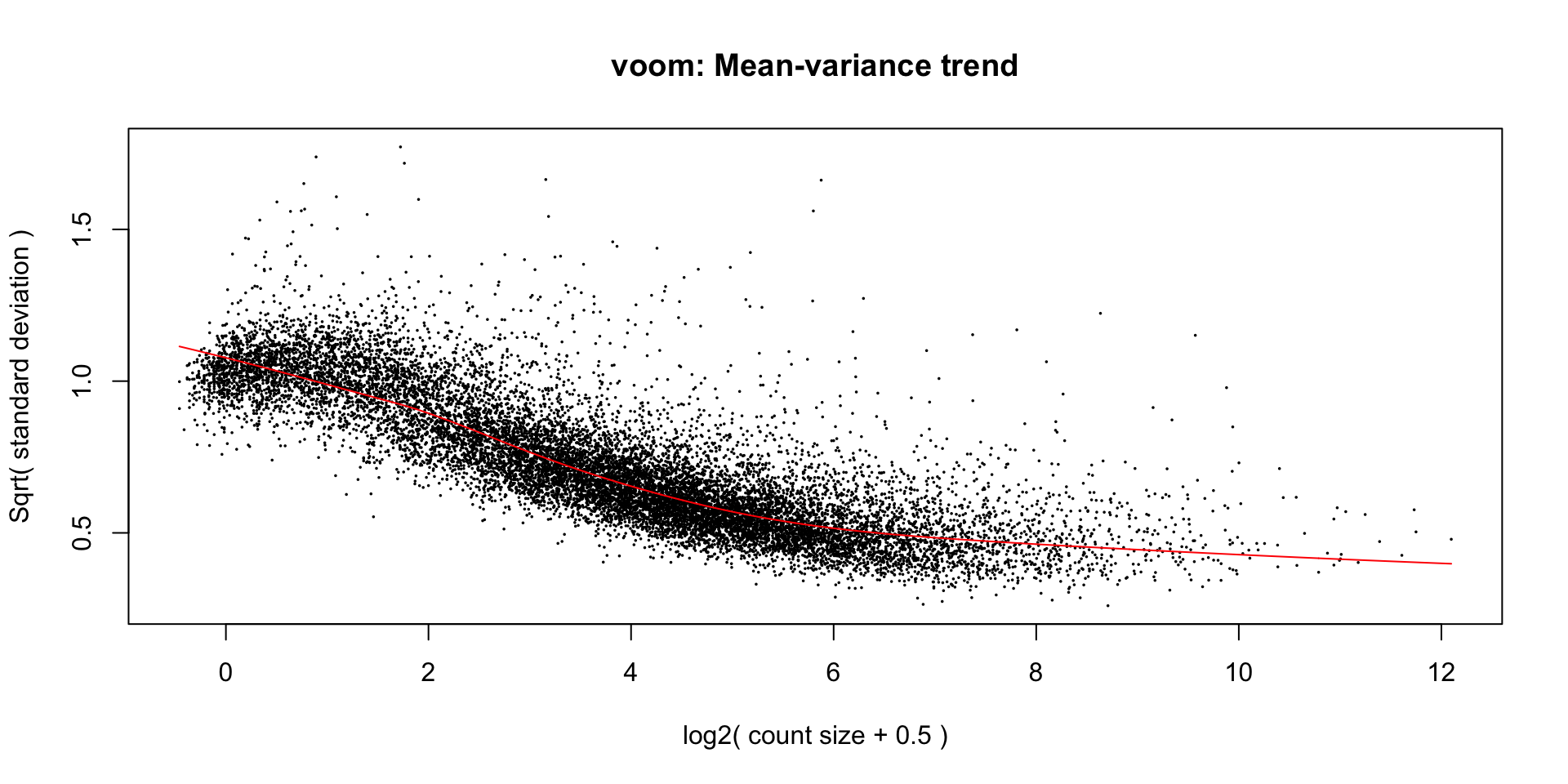
Voom transformation with observational weights
Observational & group level weights
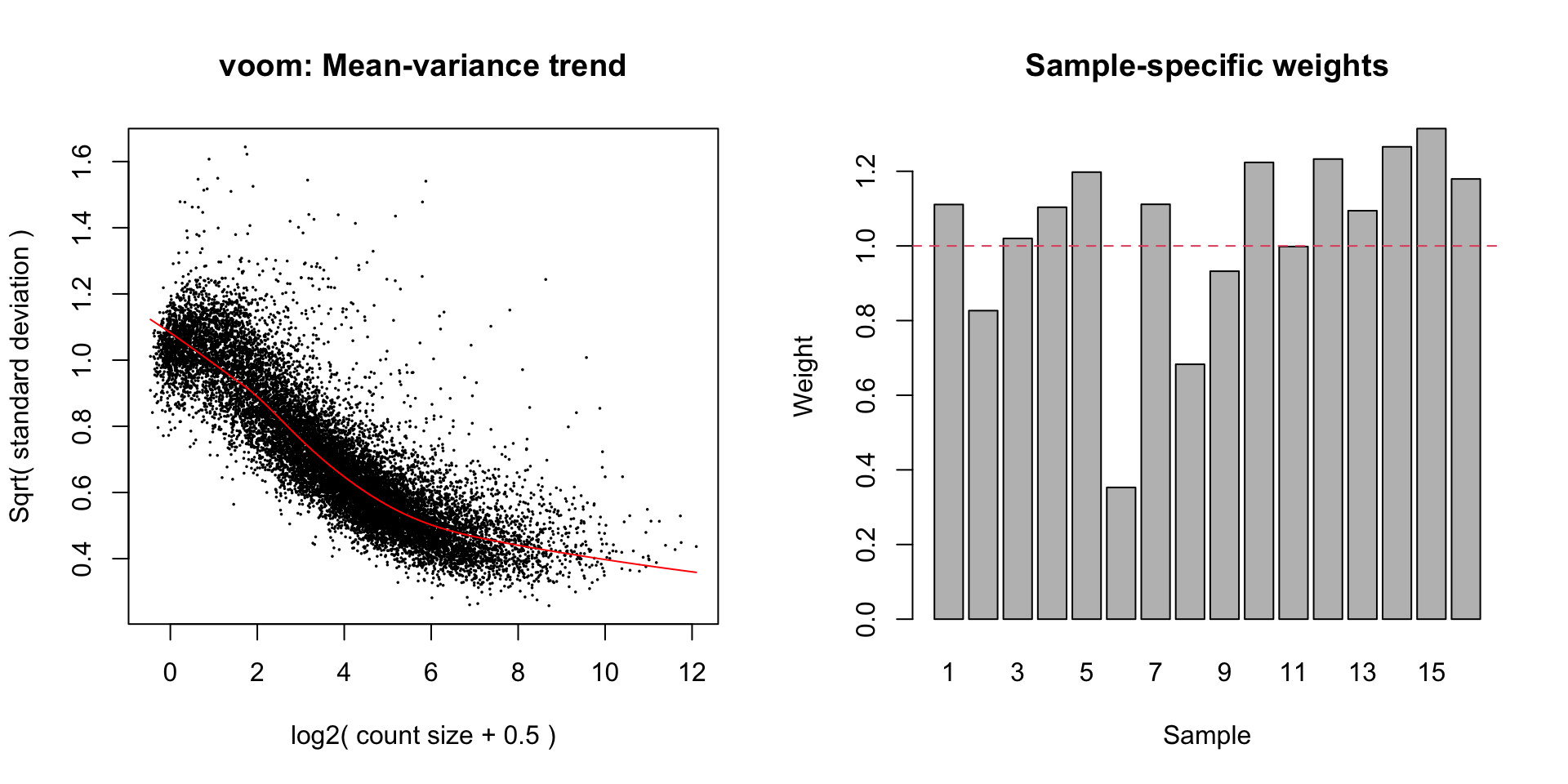
Voom transformation with observational and group-specific weights
Observational & sample level weights
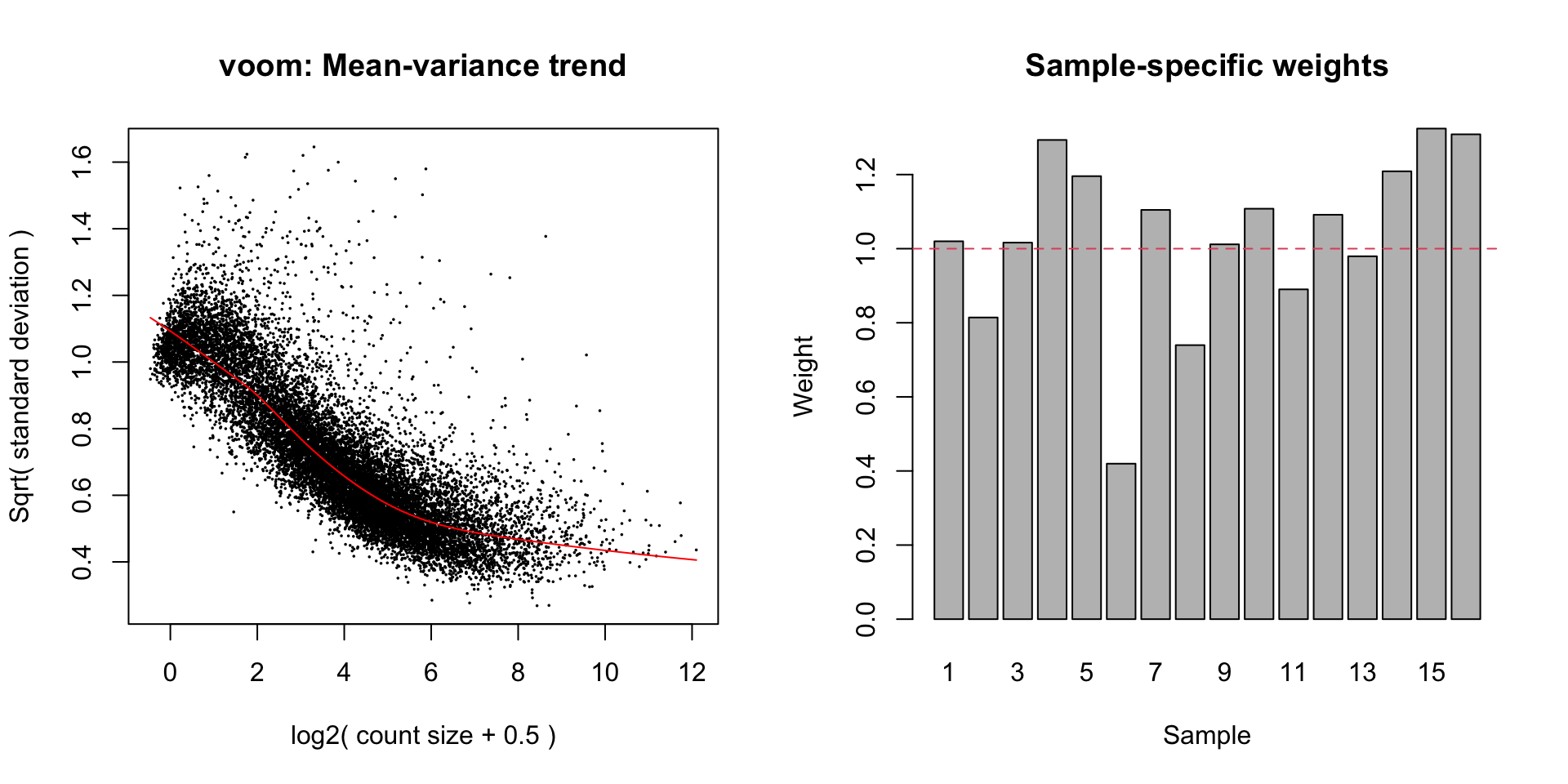
Voom transformation with observational and sample-specific weights
Apply linear model
When the list of DE genes is large, we can apply a fold change
cut-off through application of TREAT to prioritise the
genes with greater fold changes and potentially more biologically
relevant. Ideally, we are aiming for ~300 genes \(\pm\) 100 genes. Functional enrichment
analysis with this number of genes should generate meaningful
results.
Importantly, the FC threshold used in TREAT should be
chosen as a small value below which results should be ignored, instead
of a target fold-change. In general, a modest fold-change of 1.1 - 1.5
is recommended. However, it is more important to select a fold-change
cut-off that generates a sufficiently small list of DE genes.
A quick aside on the definition and interpretation of fold change and
log2FC. A fold-change (FC) refers to the
ratio of two values.
- If there is a two fold increase
(
FC = 2,log2FC = 1) betweenA vs B, thenAis twice as big asB(orAis200%ofB) - If there is a two fold decrease
(
FC = 0.5,log2FC = -1) betweenA vs B, thenAis half as big asB(orAis50%ofB)
FC=none
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 454 | 648 | 285 |
| NotSig | 13935 | 13758 | 14148 |
| Up | 359 | 342 | 315 |
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 254 | 503 | 60 |
| NotSig | 14302 | 14000 | 14624 |
| Up | 192 | 245 | 64 |
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 137 | 352 | 16 |
| NotSig | 14507 | 14274 | 14703 |
| Up | 104 | 122 | 29 |
FC=1.1
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 365 | 531 | 163 |
| NotSig | 14159 | 14049 | 14435 |
| Up | 224 | 168 | 150 |
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 151 | 364 | 6 |
| NotSig | 14518 | 14313 | 14728 |
| Up | 79 | 71 | 14 |
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 76 | 264 | 2 |
| NotSig | 14634 | 14445 | 14735 |
| Up | 38 | 39 | 11 |
FC=1.2
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 263 | 427 | 95 |
| NotSig | 14376 | 14262 | 14590 |
| Up | 109 | 59 | 63 |
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 65 | 267 | 0 |
| NotSig | 14666 | 14469 | 14748 |
| Up | 17 | 12 | 0 |
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 14 | 177 | 0 |
| NotSig | 14730 | 14566 | 14748 |
| Up | 4 | 5 | 0 |
FC=1.3
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 188 | 357 | 50 |
| NotSig | 14495 | 14372 | 14670 |
| Up | 65 | 19 | 28 |
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 17 | 195 | 0 |
| NotSig | 14728 | 14552 | 14748 |
| Up | 3 | 1 | 0 |
| DT vs veh | DT+Treg vs veh | DT+Treg vs DT | |
|---|---|---|---|
| Down | 0 | 124 | 0 |
| NotSig | 14748 | 14623 | 14748 |
| Up | 0 | 1 | 0 |
Differential Gene Expression analysis
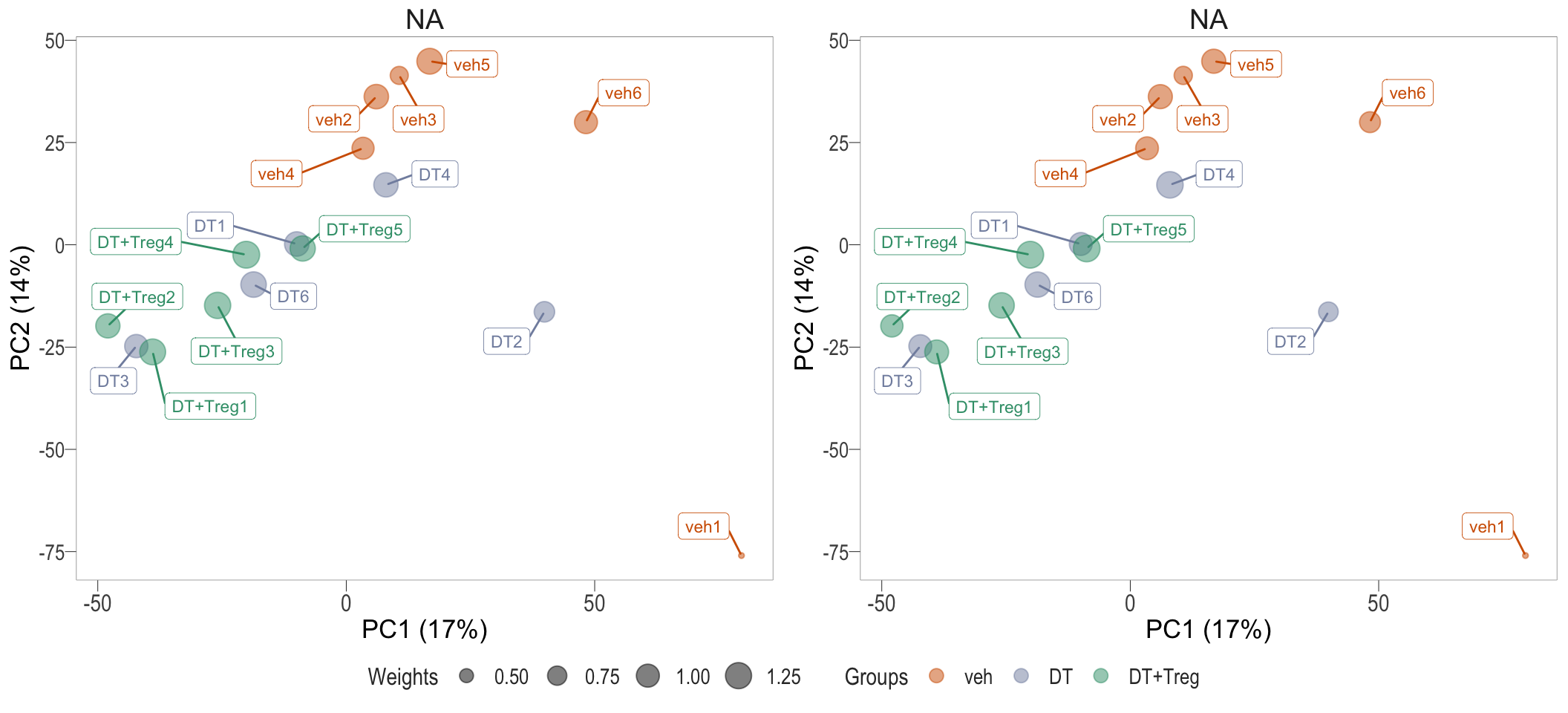
Due to the large variance in the veh group, the transformation with
observational and group-level weights were used.
Without FC cut-off (using TREAT) and an
FDR < 0.05, the DT vs DT+Treg comparison
had 45 significant DE genes (TABLE 3). This may
not be enough DE genes to perform meaningful functional
enrichment analysis downstream. Therefore, The FDR threshold is
increased to 0.1, in another word, we allow for 10% type I
error, i.e. 1 in 10 genes may be a false positive for differential
expression. Using a fold-change cut-off through application of
TREAT gives additional stringency at the costs of reducing
the list of DE genes.
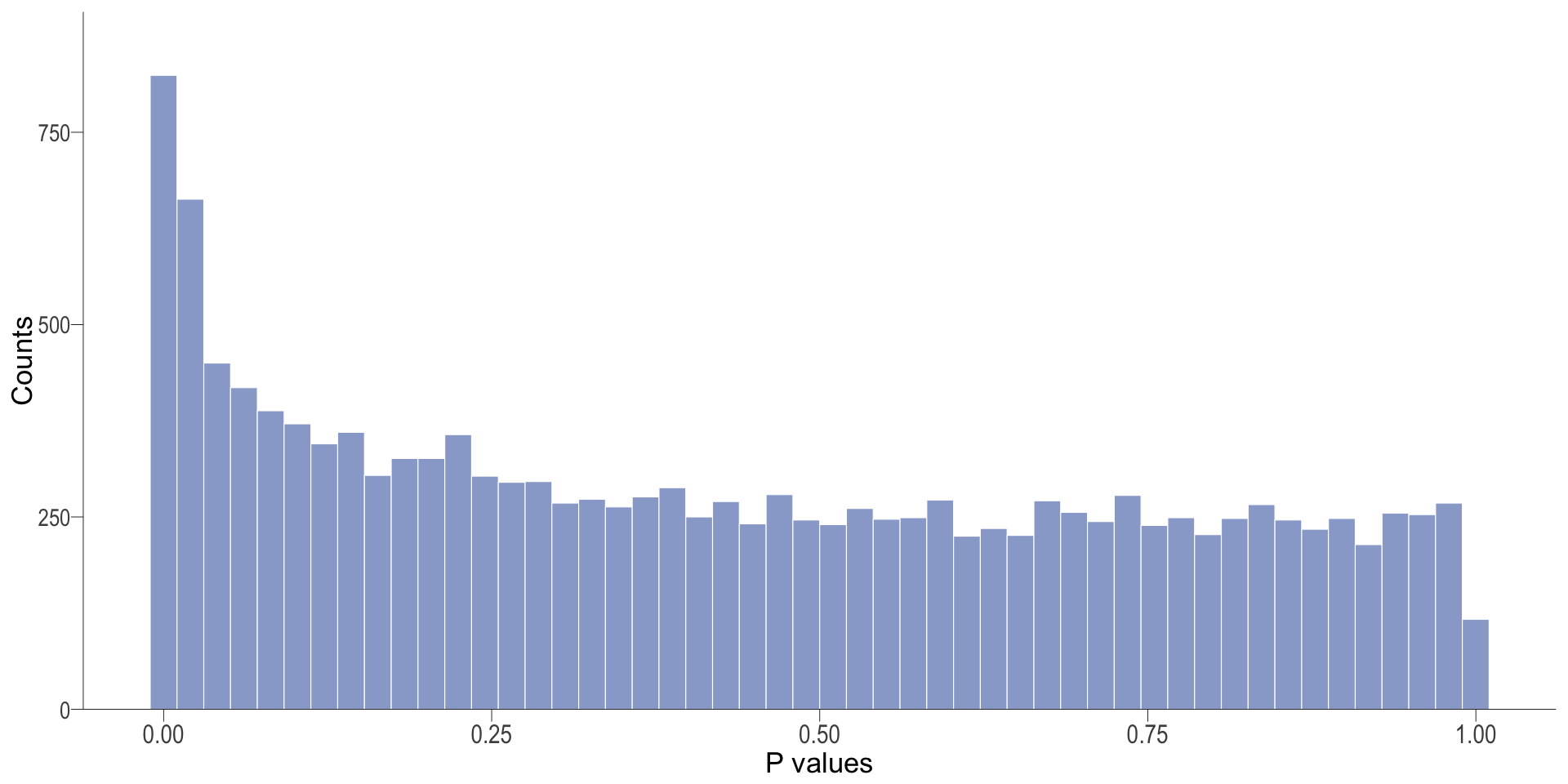
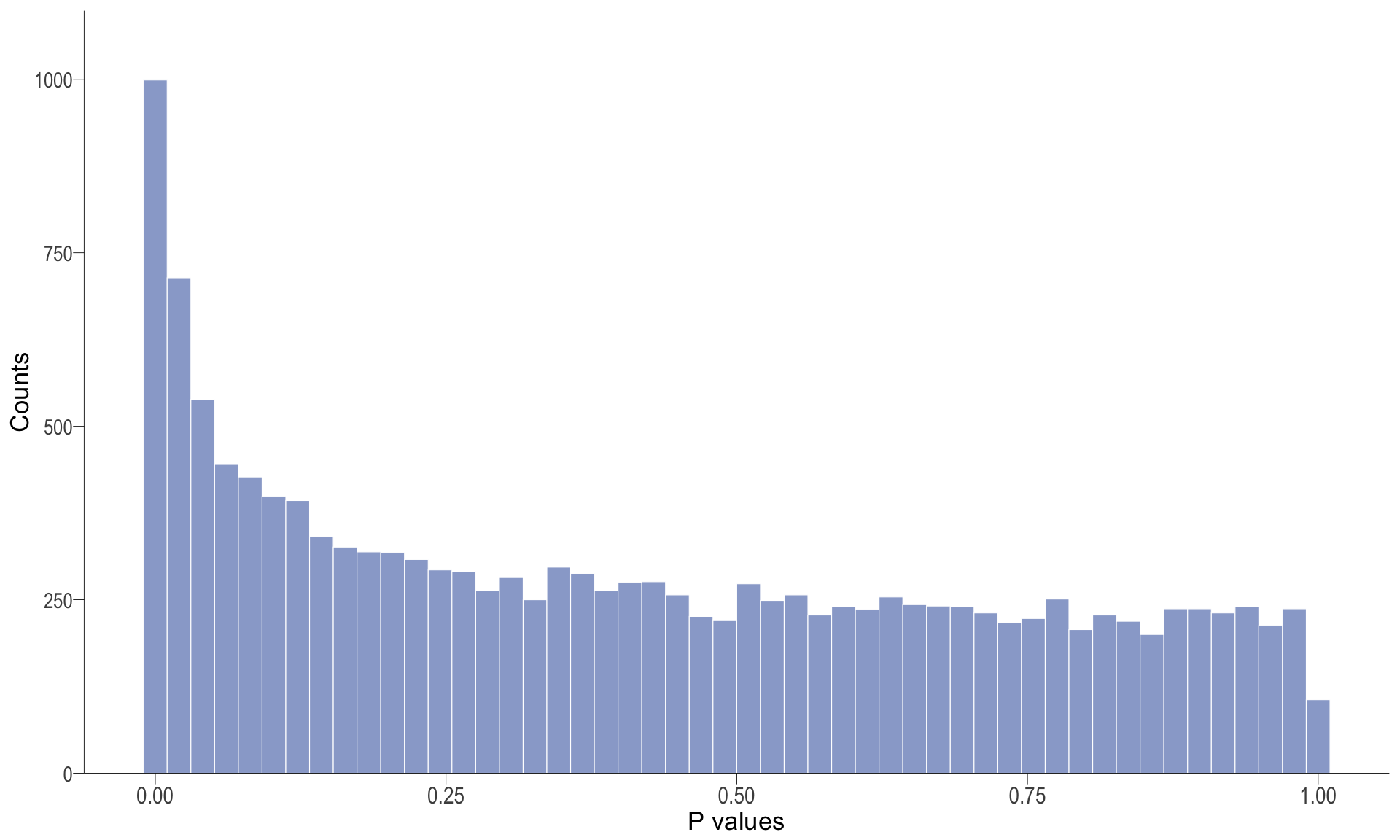
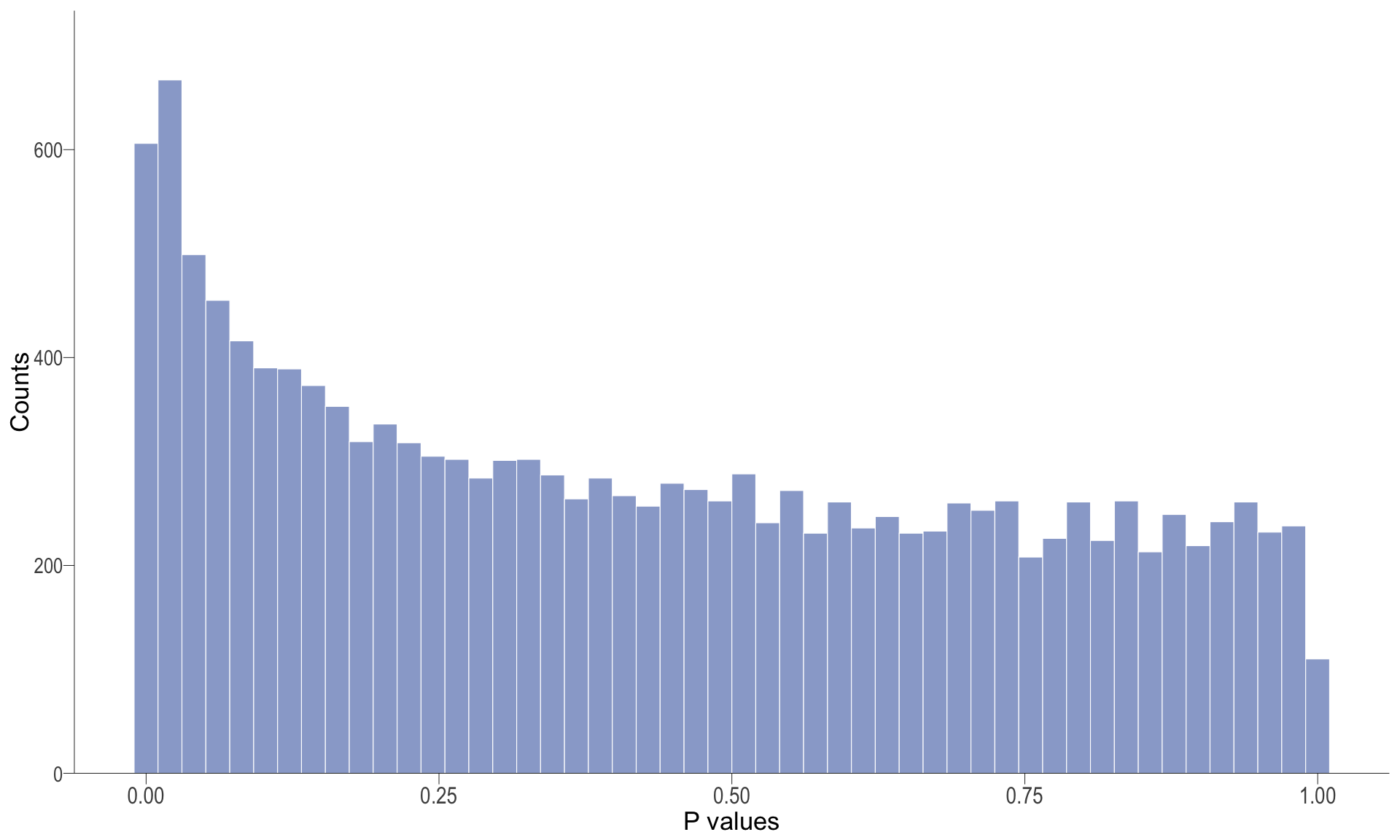
P-value histogram: illustrates the distribution of p-values. As the stringency increases (increasing FC threshold), the distribution shifts towards
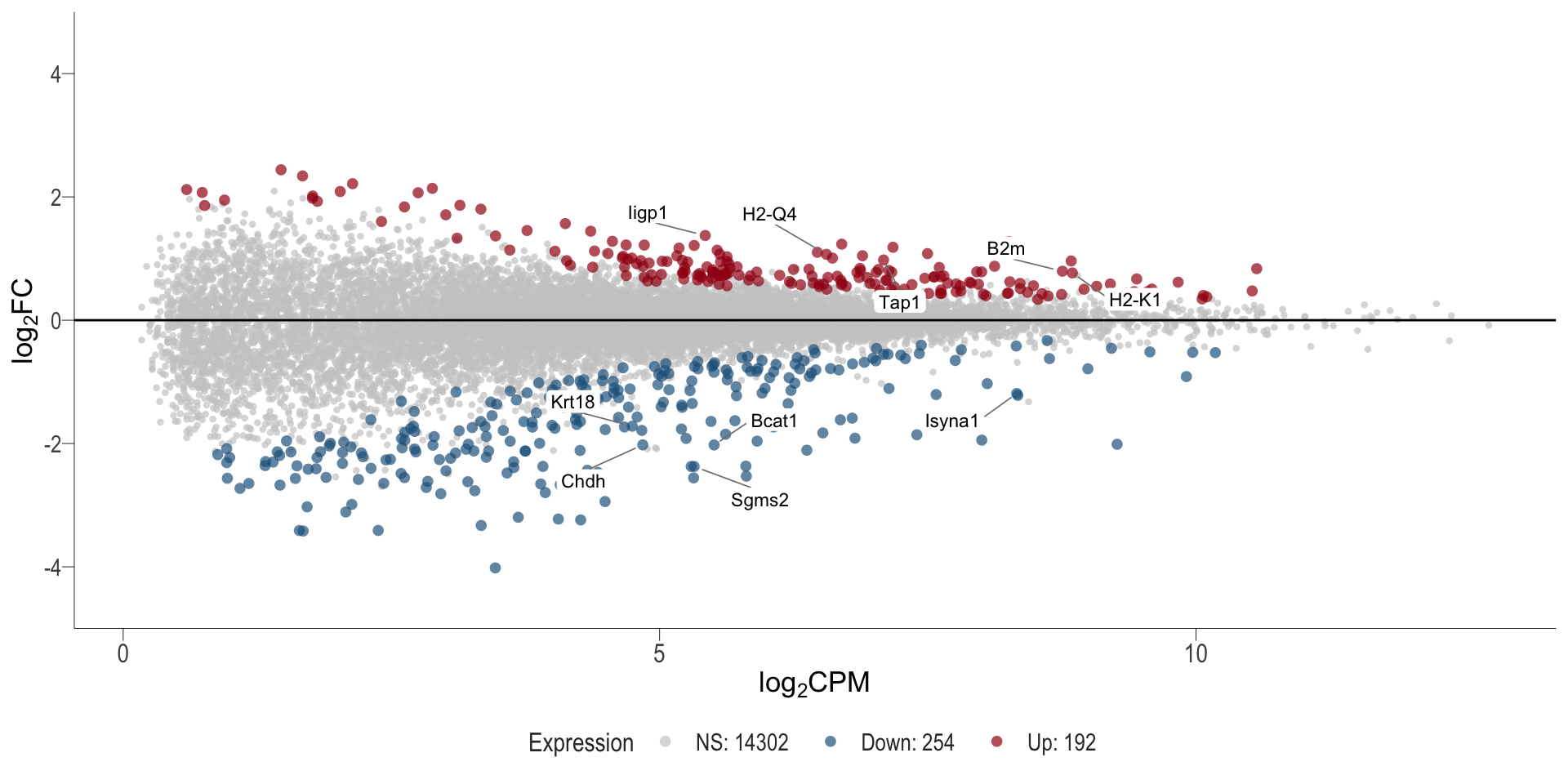
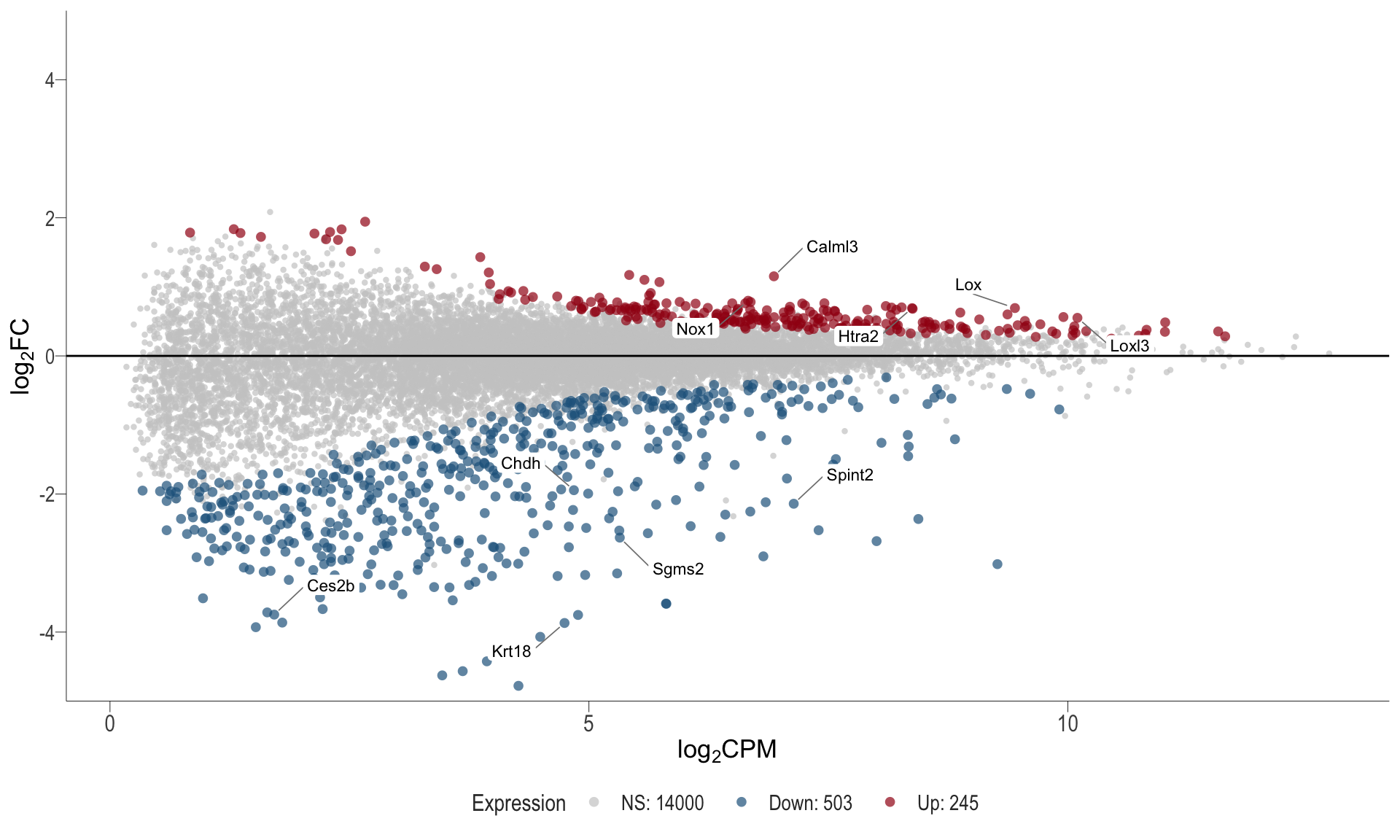
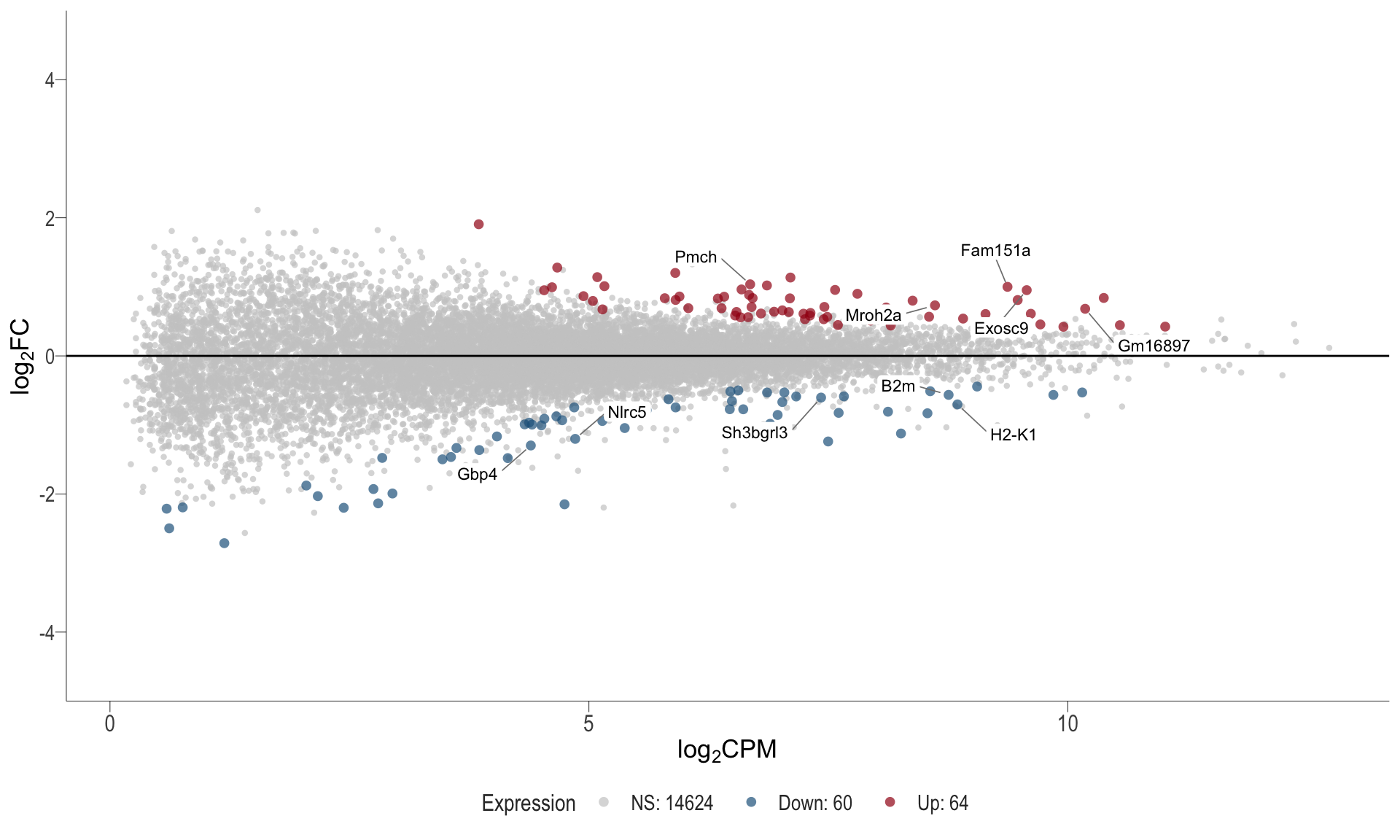
1, thus insignificant.MA plot: helps visualise and identify genes with significant changes in expression. Points deviating from the central axis often indicate differentially expressed genes, allowing assessment of the magnitude and consistency of expression changes across conditions.
- \(x-axis =\) average expression, in log counts per million (CPM)
- \(y-axis =\) log fold change between conditions
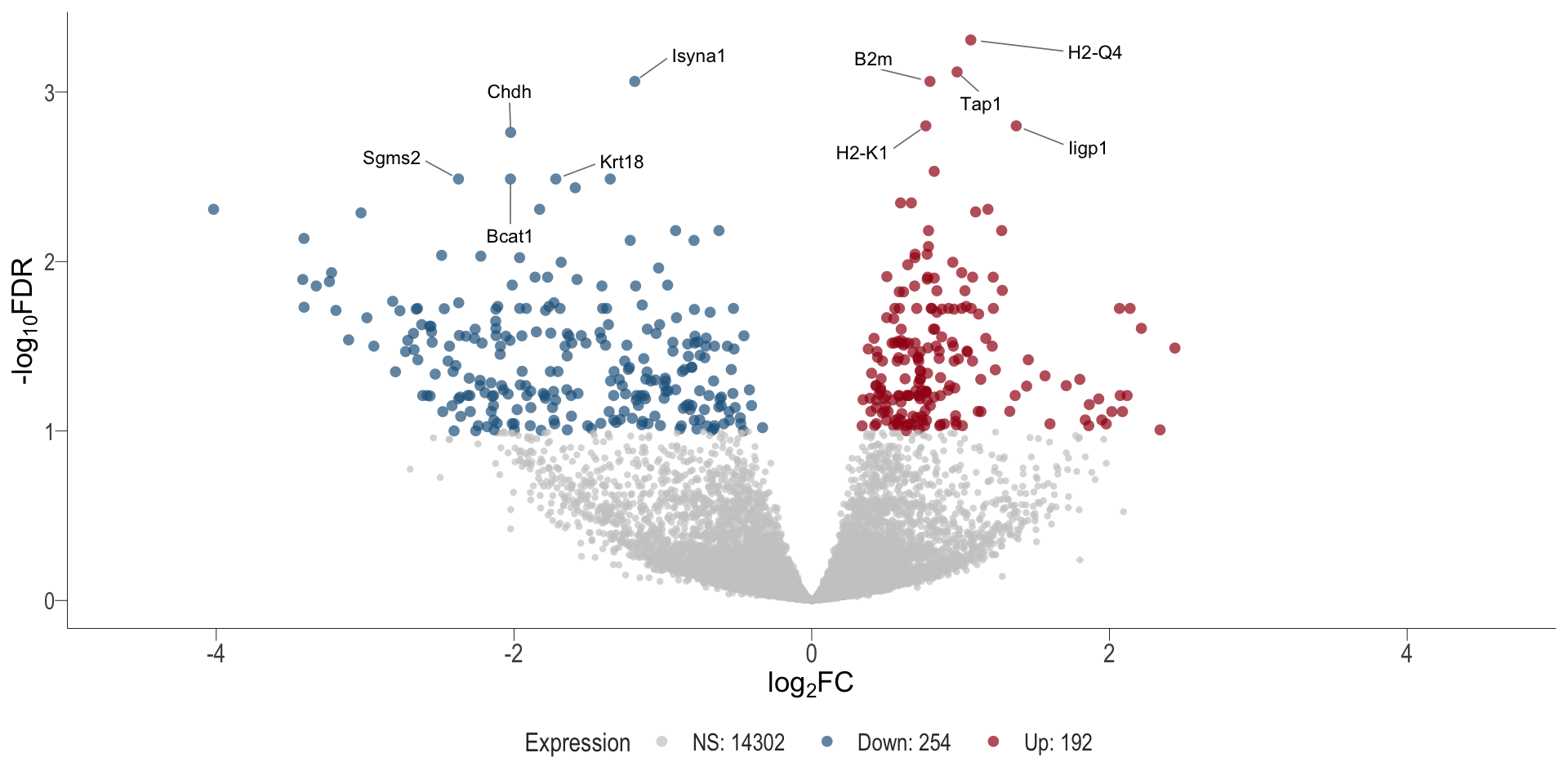
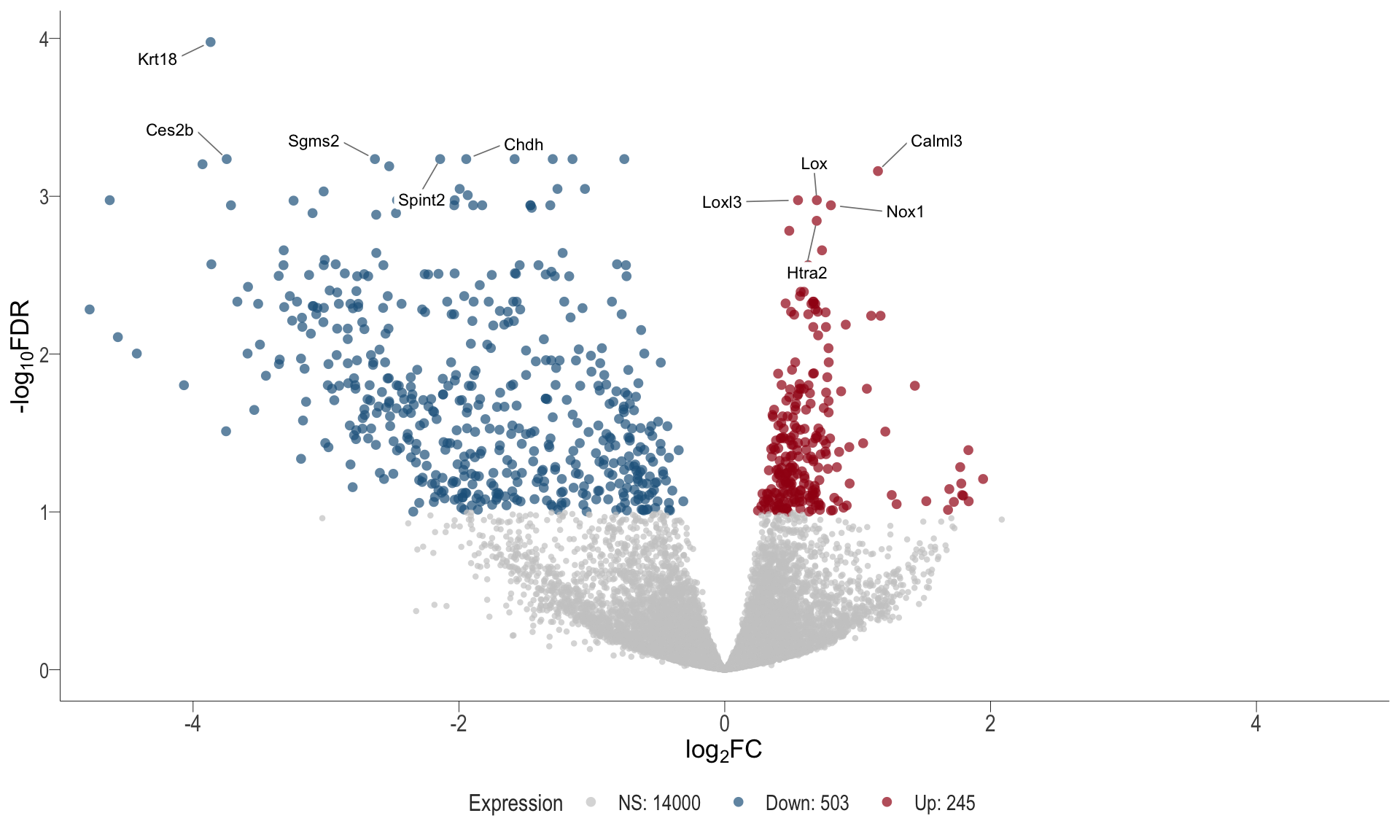
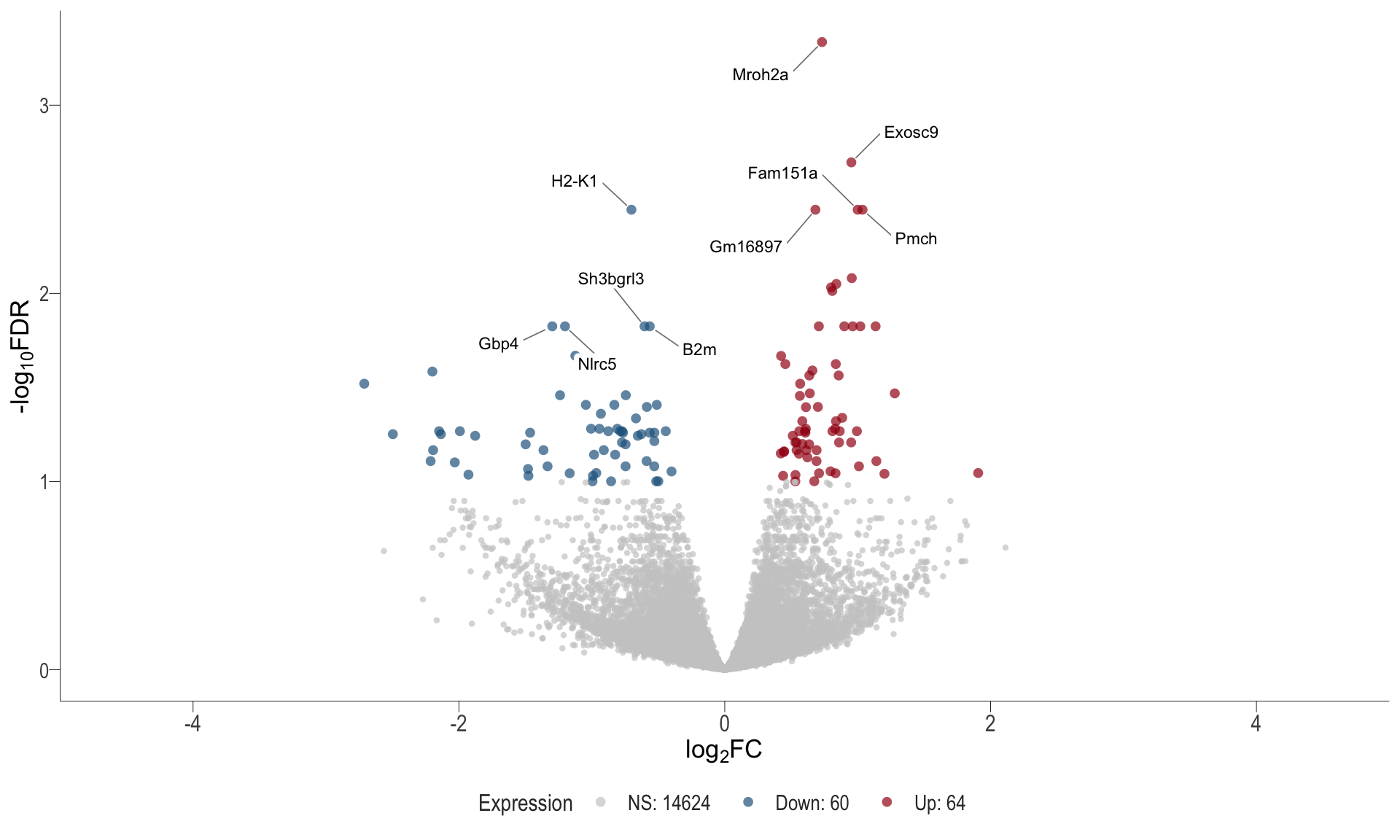
Volcano plot: shows significantly differentially expressed genes appearing as points that are both statistically significant (located at the top) and have substantial fold changes (located on the left or right sides). This visualization enables identification of genes that are statistically and biologically significant.
- \(x-axis =\) log fold change between conditions
- \(y-axis =\) negative logarithm of the FDR-adjusted p-values
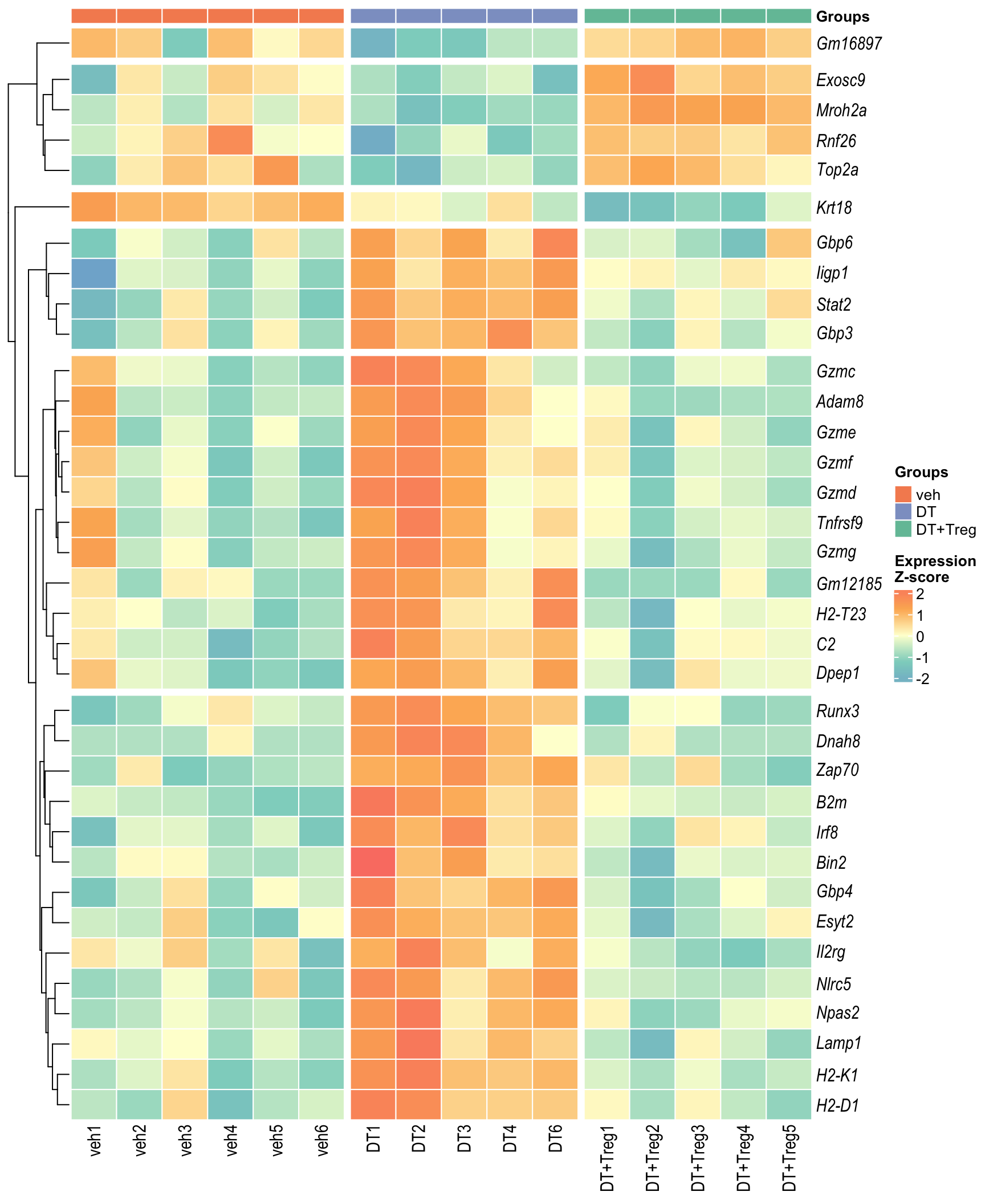
Heatmap: visualize gene expression patterns across different experimental conditions. Rows are genes, columns represent samples, and the colour intensity indicates the expression level of a gene in a specific sample. The genes are also clustered based on similar expression patterns, which provides insights into the overall structure and relationships within large datasets.
- These heatmaps illustrates the top 30 most significant DE genes
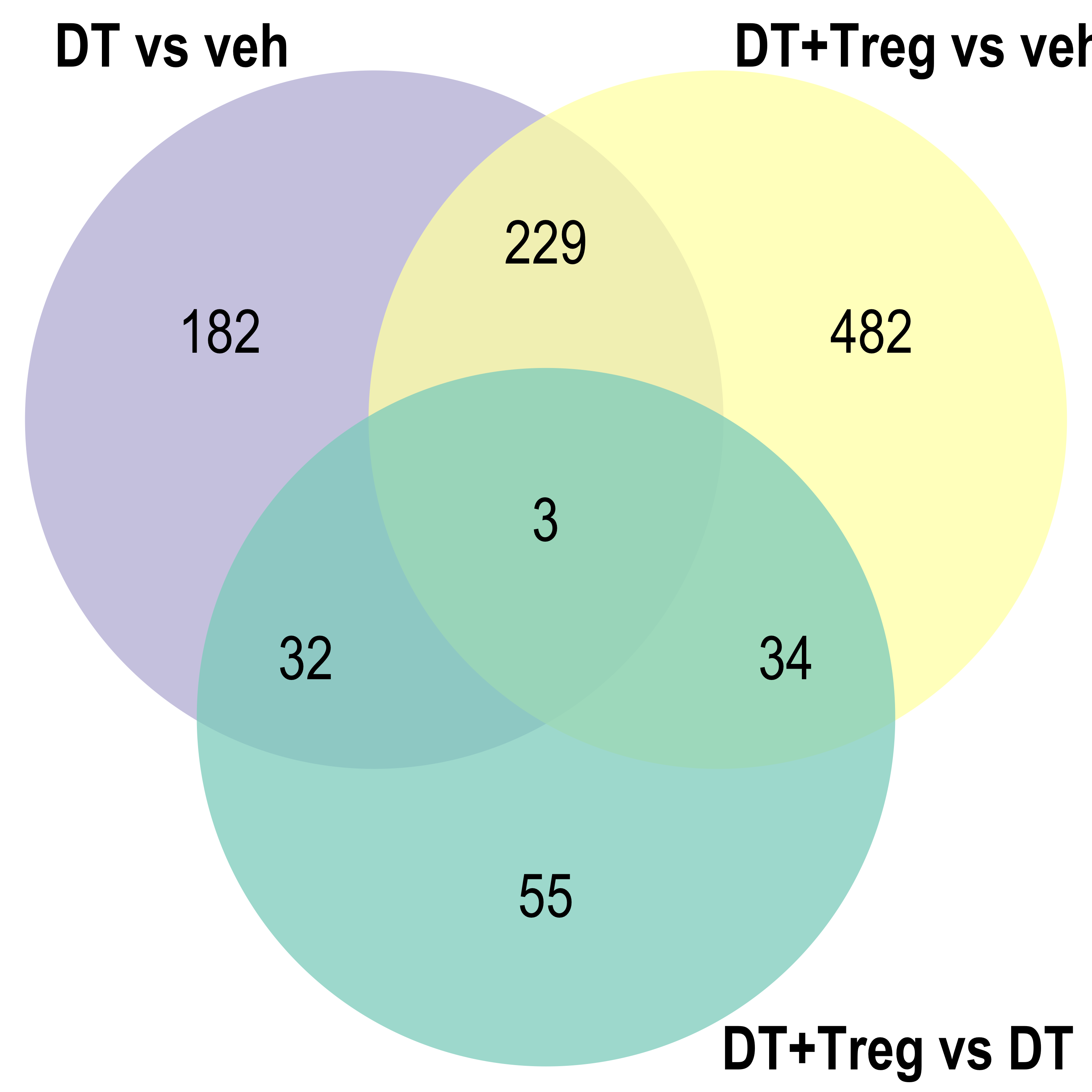
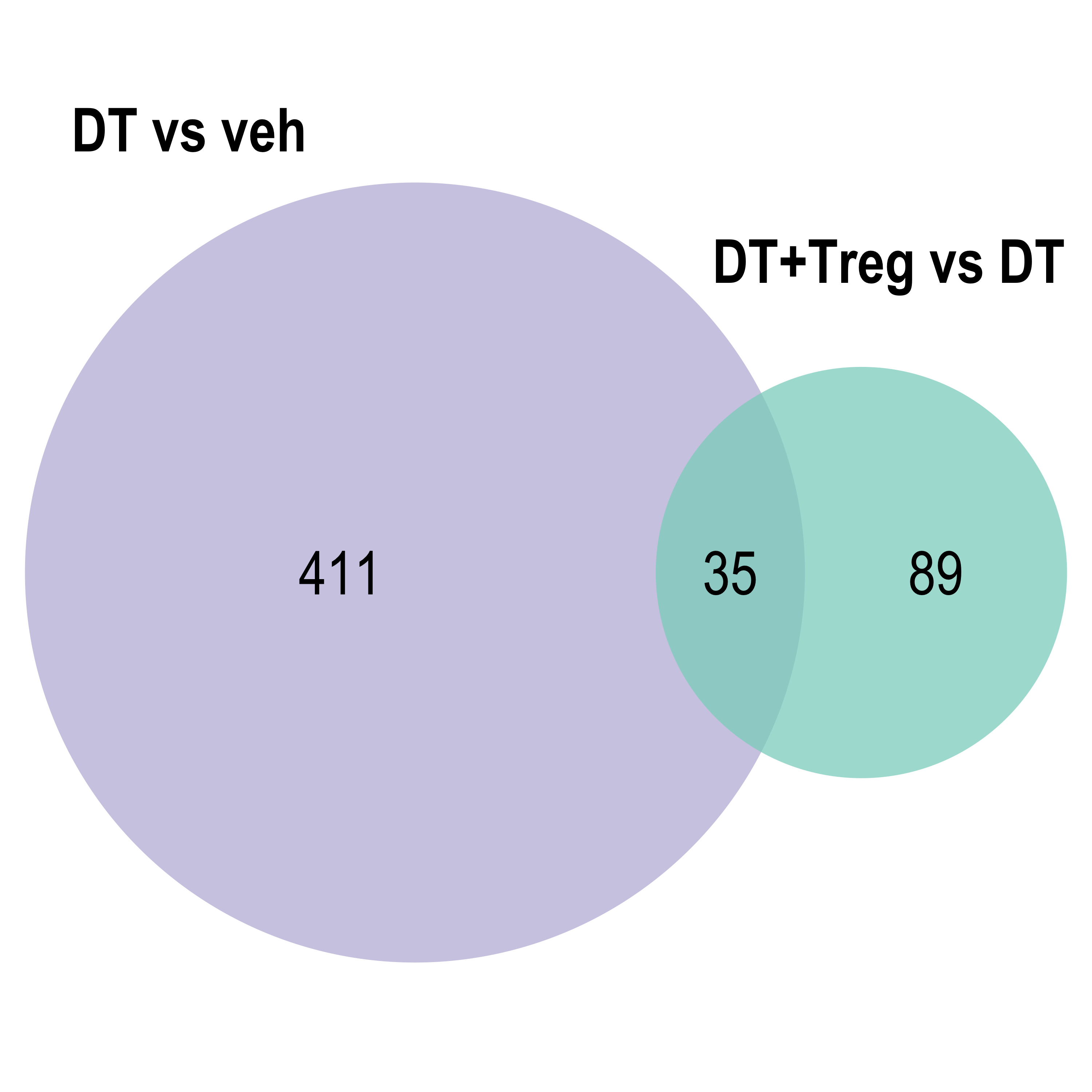
Venn diagram: visualises the significant DE gene overlap between the previous RNA-seq experiment and the current.
DT vs veh
P-val histogram
MA plot
Volcano plot
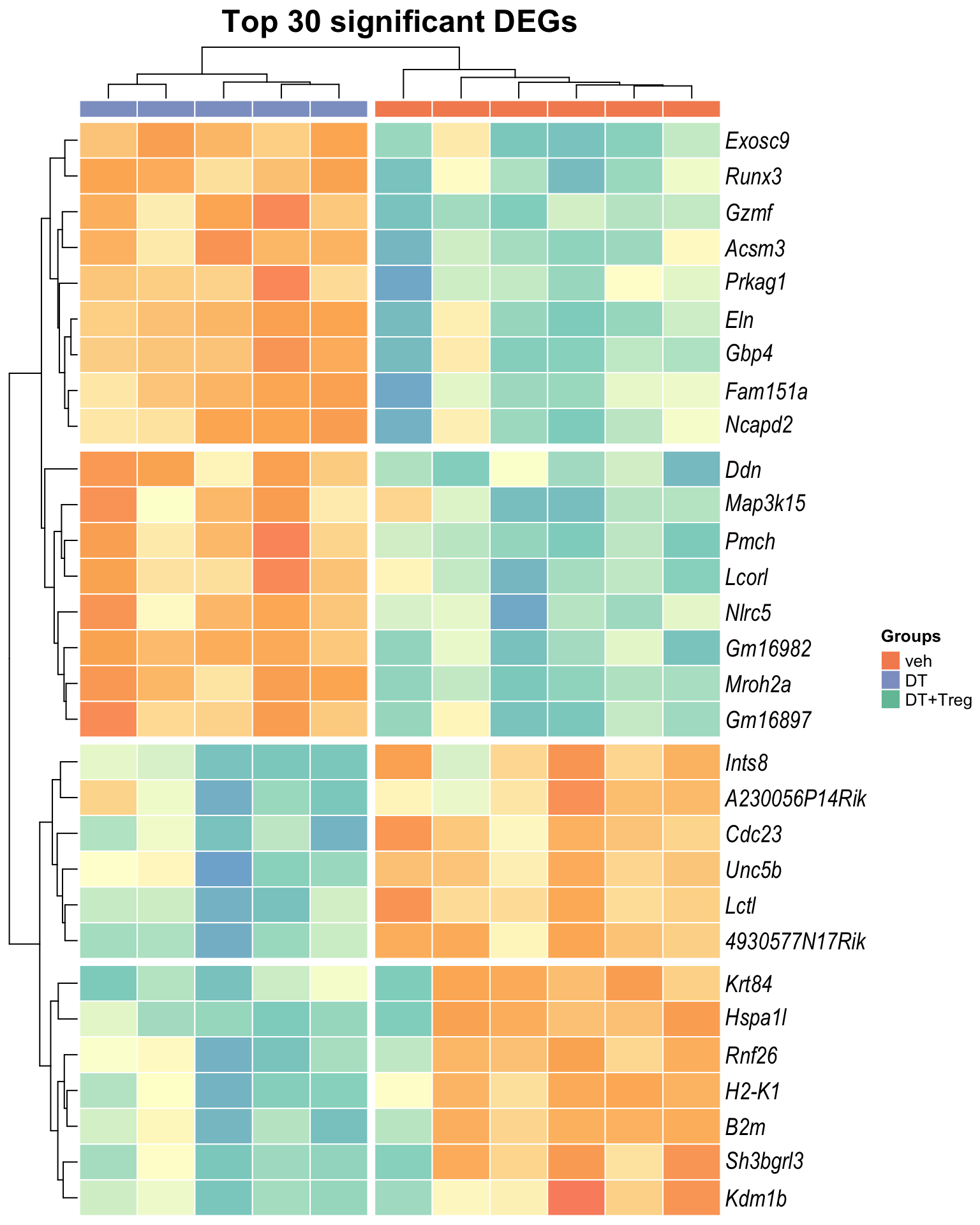
DT+Treg vs veh
P-val histogram
MA plot
Volcano plot
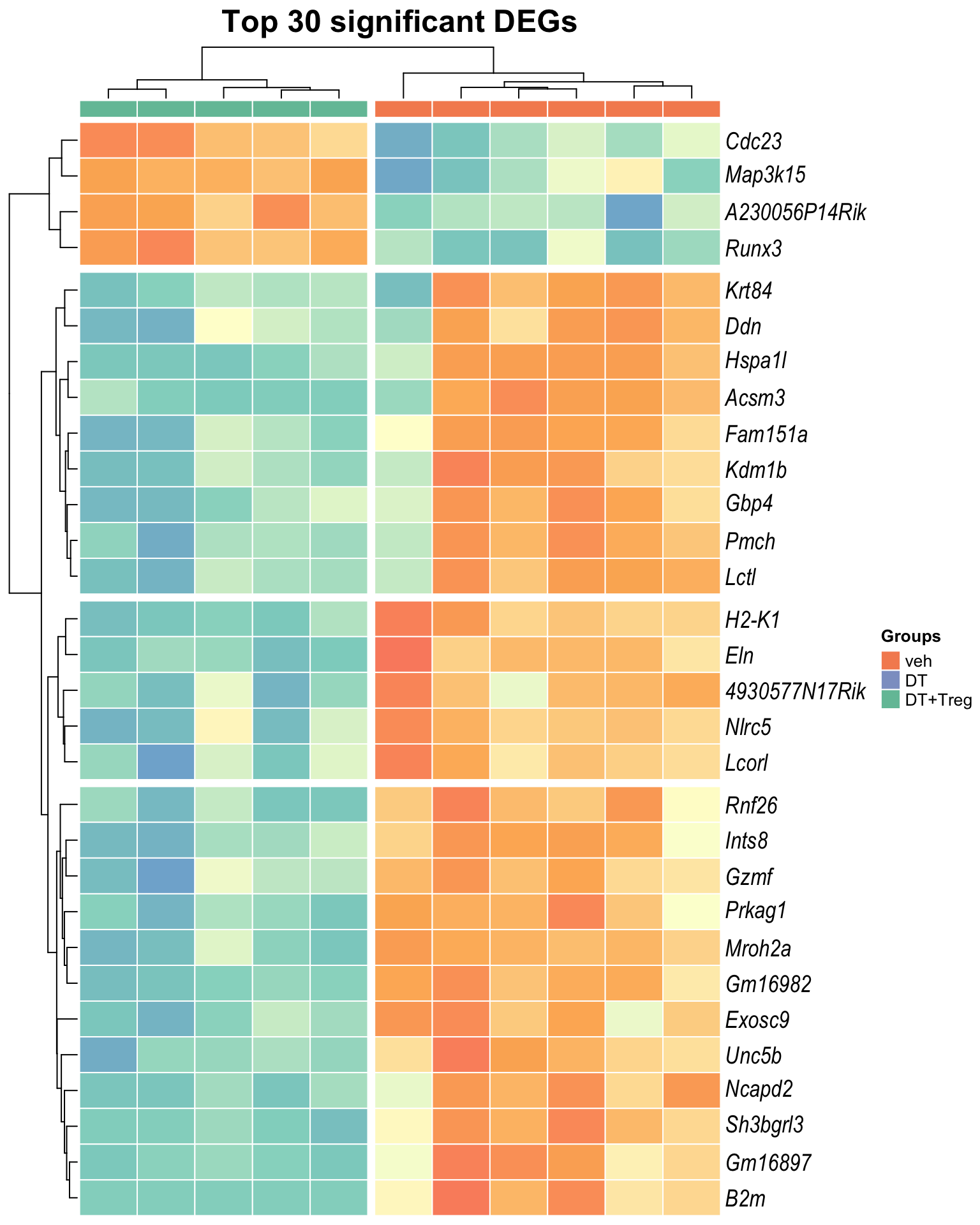
DT+Treg vs DT
P-val histogram
MA plot
Volcano plot
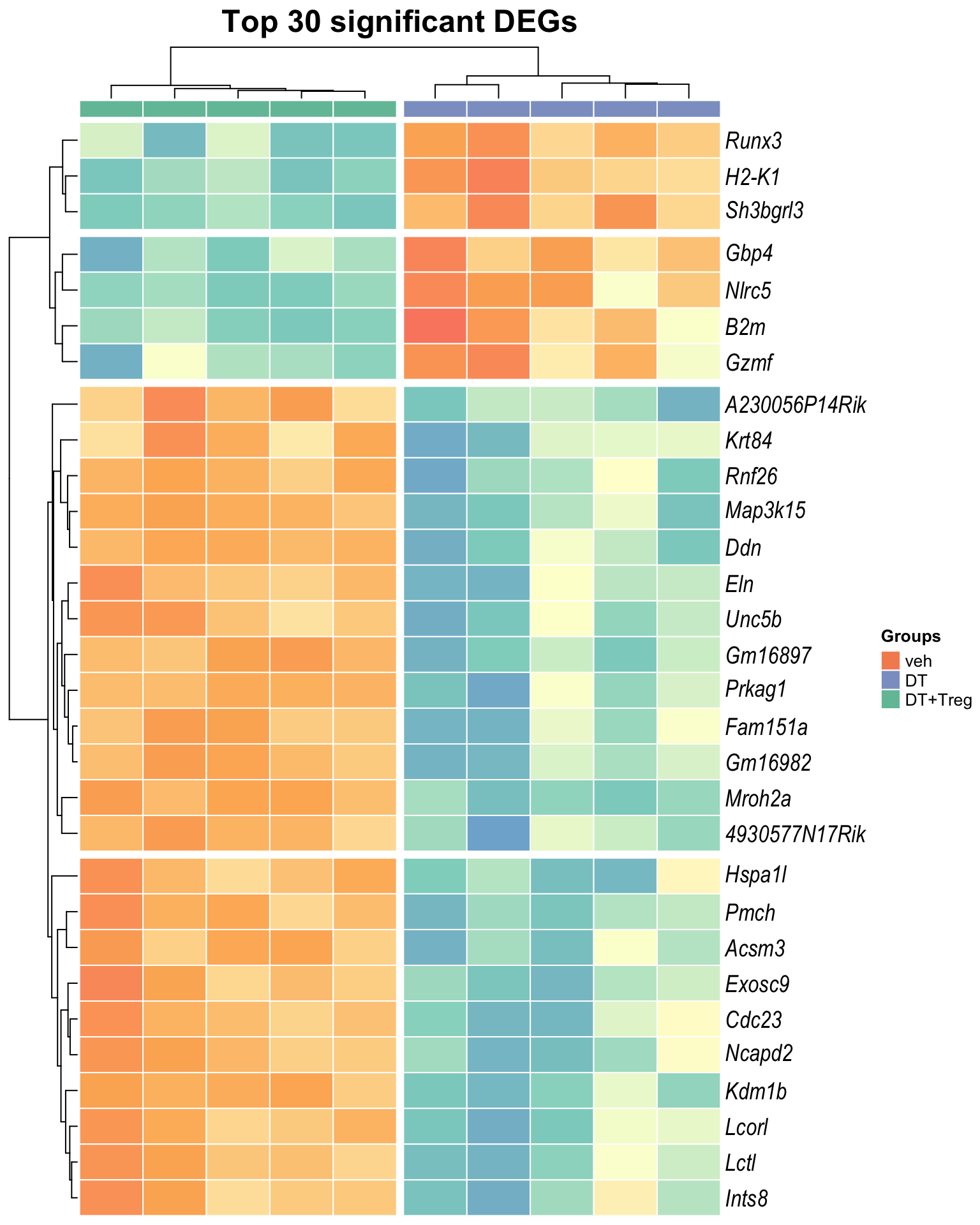
Export Data
The following are exported:
de_genes_all.xlsx - This spreadsheet contains all DE genes.
de_genes_sig.xlsx - This spreadsheet contains only significant DE genes.
R version 4.4.1 (2024-06-14)
Platform: aarch64-apple-darwin20
Running under: macOS Sonoma 14.5
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Australia/Adelaide
tzcode source: internal
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] knitr_1.48 pandoc_0.2.0 Glimma_2.14.0
[4] edgeR_4.2.1 limma_3.60.4 viridis_0.6.5
[7] viridisLite_0.4.2 ggrepel_0.9.5.9999 ggpubr_0.6.0
[10] ggplotify_0.1.2 extrafont_0.19 patchwork_1.2.0
[13] DT_0.33 VennDiagram_1.7.3 futile.logger_1.4.3
[16] pheatmap_1.0.12 cowplot_1.1.3 pander_0.6.5
[19] kableExtra_1.4.0 plyr_1.8.9 scales_1.3.0
[22] ComplexHeatmap_2.20.0 lubridate_1.9.3 forcats_1.0.0
[25] stringr_1.5.1 purrr_1.0.2 tidyr_1.3.1
[28] ggplot2_3.5.1 tidyverse_2.0.0 reshape2_1.4.4
[31] tibble_3.2.1 readr_2.1.5 magrittr_2.0.3
[34] dplyr_1.1.4 readxl_1.4.3
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 rstudioapi_0.16.0
[3] jsonlite_1.8.8 shape_1.4.6.1
[5] magick_2.8.4 farver_2.1.2
[7] rmarkdown_2.27 ragg_1.3.2
[9] zlibbioc_1.50.0 GlobalOptions_0.1.2
[11] fs_1.6.4 vctrs_0.6.5
[13] memoise_2.0.1 rstatix_0.7.2
[15] S4Arrays_1.4.1 htmltools_0.5.8.1
[17] lambda.r_1.2.4 broom_1.0.6
[19] cellranger_1.1.0 SparseArray_1.4.8
[21] gridGraphics_0.5-1 sass_0.4.9
[23] bslib_0.8.0 htmlwidgets_1.6.4
[25] futile.options_1.0.1 cachem_1.1.0
[27] whisker_0.4.1 lifecycle_1.0.4
[29] iterators_1.0.14 pkgconfig_2.0.3
[31] Matrix_1.7-0 R6_2.5.1
[33] fastmap_1.2.0 MatrixGenerics_1.16.0
[35] GenomeInfoDbData_1.2.12 clue_0.3-65
[37] digest_0.6.36 colorspace_2.1-1
[39] S4Vectors_0.42.1 DESeq2_1.44.0
[41] rprojroot_2.0.4 textshaping_0.4.0
[43] crosstalk_1.2.1 GenomicRanges_1.56.1
[45] labeling_0.4.3 fansi_1.0.6
[47] timechange_0.3.0 httr_1.4.7
[49] abind_1.4-5 compiler_4.4.1
[51] here_1.0.1 withr_3.0.1
[53] doParallel_1.0.17 backports_1.5.0
[55] BiocParallel_1.38.0 carData_3.0-5
[57] highr_0.11 Rttf2pt1_1.3.12
[59] ggsignif_0.6.4 rappdirs_0.3.3
[61] DelayedArray_0.30.1 rjson_0.2.21
[63] tools_4.4.1 httpuv_1.6.15
[65] extrafontdb_1.0 glue_1.7.0
[67] promises_1.3.0 cluster_2.1.6
[69] generics_0.1.3 gtable_0.3.5
[71] tzdb_0.4.0 hms_1.1.3
[73] XVector_0.44.0 xml2_1.3.6
[75] car_3.1-2 utf8_1.2.4
[77] BiocGenerics_0.50.0 foreach_1.5.2
[79] pillar_1.9.0 yulab.utils_0.1.5
[81] later_1.3.2 circlize_0.4.16
[83] lattice_0.22-6 tidyselect_1.2.1
[85] locfit_1.5-9.10 git2r_0.33.0
[87] gridExtra_2.3 IRanges_2.38.1
[89] SummarizedExperiment_1.34.0 svglite_2.1.3
[91] stats4_4.4.1 xfun_0.46
[93] Biobase_2.64.0 statmod_1.5.0
[95] matrixStats_1.3.0 stringi_1.8.4
[97] UCSC.utils_1.0.0 workflowr_1.7.1
[99] yaml_2.3.10 evaluate_0.24.0
[101] codetools_0.2-20 cli_3.6.3
[103] systemfonts_1.1.0 munsell_0.5.1
[105] jquerylib_0.1.4 Rcpp_1.0.13
[107] GenomeInfoDb_1.40.1 png_0.1-8
[109] parallel_4.4.1 writexl_1.5.0
[111] crayon_1.5.3 GetoptLong_1.0.5
[113] rlang_1.1.4 formatR_1.14